Content from Welcome to R!
Last updated on 2025-04-15 | Edit this page
Estimated time: 180 minutes
Overview
Questions
- Why bother learning R?
- What is RStudio? Why use it instead of “base R?”
- What am I looking at when I open RStudio?
- How do I “talk to” R and ask it to do things?
- What things can I make R build? What things can I make R do?
- How do I speak “grammatically correct” R? What are its rules and punctuation marks?
- How do I perform typical “project management” tasks in R, such as creating a project folder, saving and loading files, and managing packages?
Objectives
Recognize the several important panes found in RStudio and be able to explain what each does.
Write complete, grammatical R commands (sentences).
List R’s most common operators (punctuation marks).
Transition from communicating with R at the Console to communicating with R via script files.
Define what an R object is and explain how to assign one a name (and why you’d want to).
List several common R object and data types.
Use indices to look at (or change) specific values inside objects.
Define what an R function is and explain how to use (call) one to accomplish a specific task.
Install and turn on new R packages.
Define a working directory and explain how to choose one.
Save and load files.
Create an R Project folder and articulate the value of doing so.
Preface
Important: This course assumes you have downloaded and installed the latest version of R (go to this page and select the link near the top-center of the page matching your operating system). You also need to have downloaded and installed the latest version of RStudio (go to this page and scroll down until you see a table of links. Select the one matching your operating system). If you’ve not completed these tasks, stop and do so now.
RStudio is not strictly required for these lessons, but, while you can use R without RStudio, it’s a lot like writing a novel with quill and ink. You can do it, but it’s definitely not easier, so why would you?As such, these lessons assume you’re using RStudio. If you choose not to use RStudio, you do so at your own risk!
By contrast, this course does not assume you have any experience with coding in any programming language, including R. While prior exposure to R or another programming language would give you a head start, it’s not expected. Our goal is to take you from “R Zero” to “R Hero” as quickly but carefully as possible!
Why R?
Every R instructor gives a different answer to this question. Presumably, you’re here because you already have reasons to learn R (hopefully someone isn’t forcing you to do it!), and you don’t need more. But in case you do, here are a few:
R is one of the most powerful statistics and data science platforms. Unlike many others, it’s free and open-source; anyone can add more cool stuff to it at any time, and you’ll never encounter a paywall.
R is HUGE. There are more than 10,000 add-on packages (think “expansions,” “sequels,” or “fan-fiction”) for R that add an unbelievable volume of extra features and content, with more coming out every week.
R has a massive, global community of hundreds of millions of active users. There are forums, guides, user groups, and more you can tap into to level up your R skills and make connections.
R experience is in demand. Knowing R isn’t just cool; it’s lucrative!
If you need to make publication-quality graphs, or do research collaboratively with others, or talk with other programming languages, R has got you covered in all these respects and more.
Those are the more “boilerplate” reasons to learn R you’ll hear most places. Here are two additional ones, from UM R instructor Alex Bajcz:
> R *changed my life*, literally! Until I got exposure to R as a
> Ph.D. student, I'd ***never*** have said I had ***any*** interest
> in programming or data science, let alone an interest in them as a
> ***career***. Be on the computer all day? *Never*! I'm an
> *ecologist*! I study *plants*–I'm meant to be *outside*! But, fast
> forward ten years, and here I am—I'm a quantitative ecologist who
> uses R *every day* who doesn't *want* to imagine things being any
> other way! Thanks to R, I discovered a passion I never would've
> known I had, and I'd have missed out on the best job I could
> imagine having (even better, it turns out, than the job I'd
> trained for!).
>
> R also makes me feel *powerful*. This isn't a macho or petty
> thing; it's earnest. I *still* remember the first time I had R do
> something for me that I didn't want to do myself (because it'd
> have taken me hours to do in Microsoft Excel). Putting a computer
> to work for you, and having it achieve something awesome for you,
> perfectly, in a fraction of the time, is an *incredible* feeling.
> Try it—you just might like it as much as I do!Hopefully, you’ll leave these lessons with some new reasons to be excited about R and, who knows, maybe learning R will change your life too!
How we’ll roll
The attitude of these lessons can be summarize like this: Learning a programming language (especially if you’re not a trained programmer and have no immediate interest in becoming one) should be treated like learning a human language. Learning human languages is hard! It took you many years to learn your first one, and I bet you still sometimes make mistakes! We need to approach this process slowly, gently, and methodically.
Granted, most programming languages (R included) are simpler than human languages, but not by much. It’s the steep learning curve that scares most people off, and it’s also why courses that teach R plus something else (such as statistics) generally fail to successfully teach students R—learning R by itself is hard enough!
So, in these lessons, we’ll only teach you R; we won’t cover statistics, graphic design principles, or data science best practices. You can pick those skills up after you feel confident with R!
Instead, our entire focus will be getting you comfortable and confident with R. This means, among other things, helping you to:
Navigate RStudio.
Understand R’s vocabulary (its nouns and verbs, plus its adjectives and adverbs).
Understand R’s grammar and syntax (what symbols to use and when, what is and isn’t allowed, and what a correct “sentence” in R looks like).
Work with data in R (R, as a programming language, is designed around working with data—much more so than other similar languages).
And we’ll teach you this stuff one baby step at a time. Speaking of which…
(Section #1) Baby steps
When you were very little, you learned things mostly through trial and error. You did something, and you observed what happened. You accumulated bits of understanding one by one until, eventually, you could piece them together into something much greater.
We’ll take a similar approach to learn R: we’re often going to just do something and see what happens. Then, we’ll step back and discuss why it happens. Each time, we’ll be one step closer to not just being able to use R but being able to understand R!
The first thing you need to do is find the pane called “Console” in RStudio. It’s often in the lower-left (but it could be elsewhere; when you open RStudio for the first time, it might be the entire left-hand side of your screen).
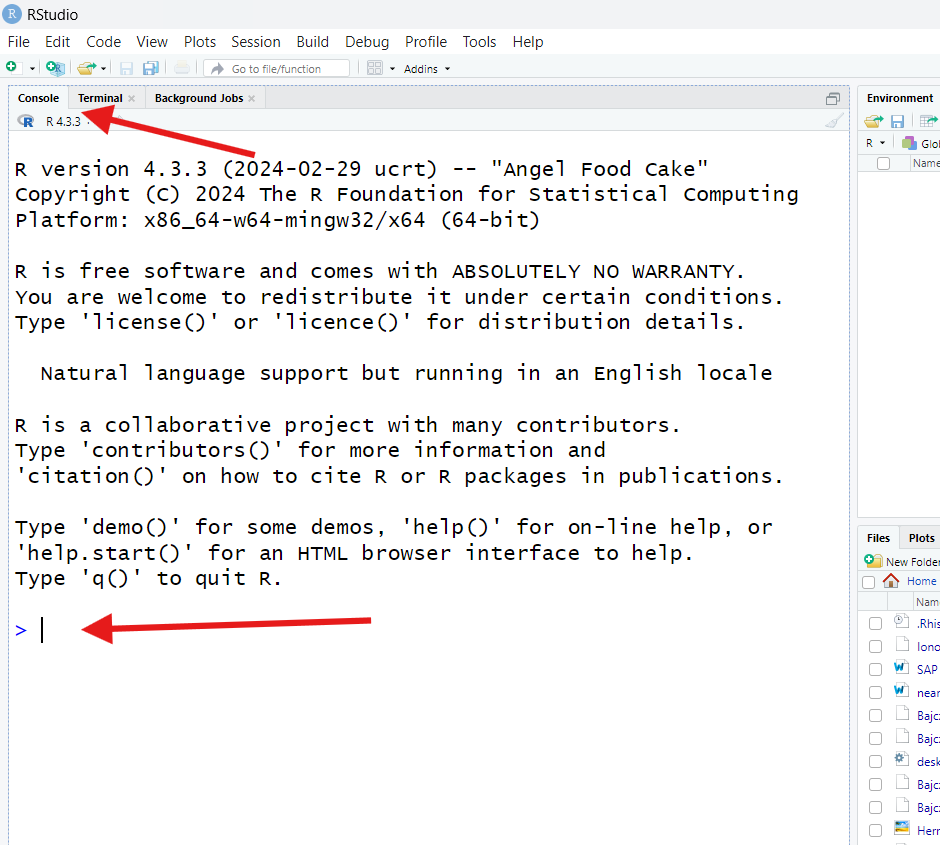
You’ll know you’ve found it if you see a > symbol at
the bottom and, when you click near that symbol, a
cursor (a blinking vertical line) appears next to
it.
Click near the > to receive the cursor. Then, type
exactly this:
R
2 + 3
Then, press your enter/return key. What happens?
You should receive something looking like this:
OUTPUT
[1] 5Since we know that two plys three is five, we can infer that R took
the values 2 and 3 and added them, given that
R sent 5 back to us. That must mean that + is
the symbol (programmers would call it an operator) R
uses as a shorthand for the verb “add.”
We’ve written our first R “sentence!” In programming, a complete, functional sentence is called a command because, generally, it is us commanding the computer to do something—here, add two values.
Challenge
Next, type exactly 2+3 into the Console and hit
enter/return. Then, type exactly 2+ 3 and hit enter/return.
What does R produce for us in each case? What does this tell us?
R doesn’t produce anything new, hopefully! We should get
5 back both times:
R
2+3
OUTPUT
[1] 5R
2+ 3
OUTPUT
[1] 5This teaches us our first R grammar (non-)rule—spaces don’t (usually) matter in R. Whether we put spaces in between elements of our command or not, R will read and act on (execute) them the same.
However, spaces do help humans read commands. Since you are a human (we assume!), it will probably help you read commands more easily to use spaces, so that’s what we’ll do with all the code in these lessons. Just know you don’t need them because they don’t convey meaning.
Math: The universal language
Next, type and run the following three commands at the Console (hit enter/return between each):
R
2 - 3
2 * 3
2 / 3
What does R produce for you? What does this tell us?
Here’s what you should have observed:
OUTPUT
[1] -1OUTPUT
[1] 6OUTPUT
[1] 0.6666667What that must mean is that -, *, and
/ are the R operators for subtraction,
multiplication, and division, respectively.
If nothing else, R is an extraordinary (if overpowered and over-complicated) calculator, capable of doing pretty much any math you might need! If you wanted, you could use it just for doing math.
Challenge
Next, try running exactly (2 + 3) * 5. Then, try running
exactly 2^2 + 3. What does R produce in each case, and
why?
In the first case, you’ll get 25 (and not 17, as you
might have expected). That’s because parentheses are R’s
operators for “order of operations.” Remember
those from grade school?? Things inside parentheses will happen
before things outside parentheses during math
operations.
So, 2 and 3 are added before any
multiplication occurs (try removing the parentheses and re-running the
command to confirm this).
In the second case, you’ll get back 7, as though
2^2 is really 4 somehow. This is because the
caret operator ^ is used for exponents in R. So,
2 gets raised to the power of 2
before any addition occurs, just as order of operations dictate
that it should.
These examples show that you can do any kind of math in R that you learned in school!
So far, we’ve seen what R will do for us if we give it complete commands. What happens if our command is incomplete?
At the Console, run exactly this:
What does R produce for you (or what changes)?
Your Console should now look something like this:

R has replaced the ready prompt > we
normally see in the Console with a + instead. This is R’s
waiting prompt, i.e., it’s waiting for us to
finish our previous command.
If we typed 3 and hit enter/return, we’d finish our
command, and we’d observe R return 5 and then switch back
to its ready prompt. If, however, we instead put in
another complete command, or another incomplete command that doesn’t
quite complete the previous command, R will remain confused and continue
giving us its waiting prompt. It’s easy to get “stuck” this way!
Callout
If you ever can’t figure out how to finish your command and get “stuck” on R’s waiting prompt, hit the “Esc” key on your keyboard while your cursor is active in the Console. This will clear the current command and restore the ready prompt.
No need to console me
By now, you might have realized that the Console is like a “chat window” we can use to talk to R, and R is the “chatbot” on the other side, sending us “answers” to our “questions” as quick as it can.
If we wanted, we could interact with R entirely through the Console (and, in fact, “base R” is more or less just a Console!).
However, we probably shouldn’t. Why not? For one thing, the Console is an impermanent record of our “chats.” If we close R, the contents of the Console get deleted. If we’d done important work, that work would be lost! Plus, the Console actually has a line limit—if we reach it, older lines get deleted to make room.
Sure, we could copy-paste the Consoles’ contents into another document on a regular basis, but that’d be a pain, and we might forget to do it sometimes. Not good!
In programming, the goal is to never lose important work! The Console just isn’t designed to prevent work loss. Thankfully, we have a better option…
Staying on-script
Let’s open something called a script file (or “script” for short). Go to “File” at the top of your RStudio window, select “New File,” then select “R Script File.” Alternatively, you can click the button in the top-left corner of the RStudio window that looks like a piece of paper with a green plus sign, then select “R Script.”
Either way, you should now see a screen like this:
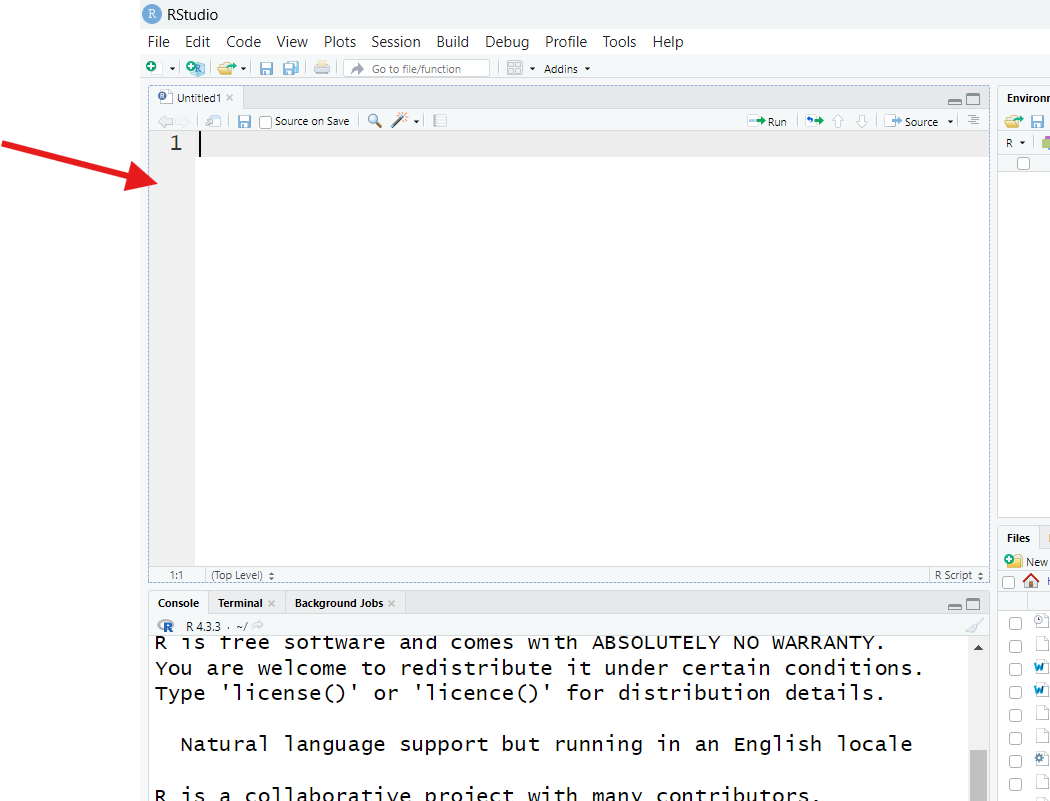
RStudio is displaying a blank script file. If you’re new to programming, a “script file” might sound scary, but a script file is just a text file, like one created in Microsoft Word or Google Docs, but even more basic—you can’t even format the text of one in any meaningful way (such as making it bold or changing its size).
Specifically, a script is a text file in which we write commands we are considering giving to R, like we’re writing them down in a notepad while we figure things out. Script files let us keep a permanent record of the code we’re crafting, plus whatever else we’re thinking about, so we can reference those notes later.
You might be wondering: “Why can’t I just have a Word file open with my code in it, then? Why bother with a special, basic text file?” The answer: In RStudio, script files get “plugged into” R’s Console, allowing us to pass commands from our script directly to the Console without copy-pasting.
Let’s see it! In your script file, type the following, then hit enter/return on your keyboard:
R
2 + 3
What happens in the Console?
The answer, you’ll discover, is nothing! Nothing new print to the Console. In our script, meanwhile, our cursor will move to a new line, just like in would in a word processor. This shows us that the “enter” key doesn’t trigger code to run in a script file, like it would at the Console.
Put your cursor back on the same line as 2 + 3 in your
script by clicking anywhere on that line, then find the button that says
“Run” in the upper-right corner of your Script pane (it looks like a
piece of paper with a green arrow through it pointing right).
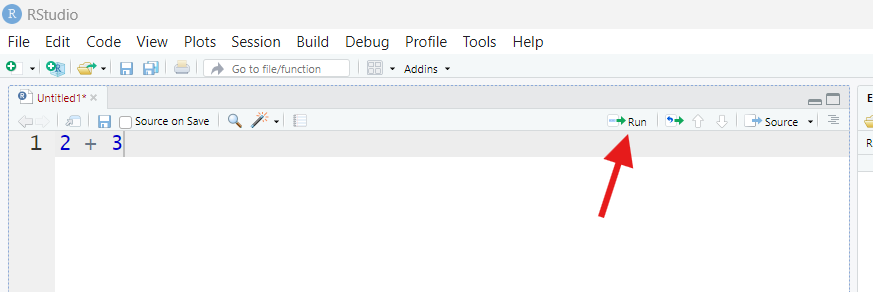
Once you find that button, press it.
What happens? This time, we observe our command and R’s response appear in the Console, as though we’d typed and ran the command there (but we didn’t!).
When we hit the “Run” button, R copied our command from our script file to the Console for us, then executed it.
This is the magic of script files:
- They serve as a permanent record of our code.
- They give us a place to “tinker” because we can decide if and when we run any code we put in one. Half the code in a script could be “experimental junk” and that’s ok, so long as you don’t personally find that confusing.
- You can run whichever commands from your script file whenever you want to, no copy-pasting necessary.
- When your commands get longer (wait until you see how long some
ggplot2commands get!), it’s easier to write them out and then format them to be human readable in a script file than it would be at the Console.
So, few everyday R users code exclusively at the Console these days. Instead, they code in scripts, letting R “teleport” relevant commands to the Console when they’re ready. As such, we encourage you to code entirely from a script for the rest of these lessons.
Leaving a legacy
You may have noticed that, when you first typed something in your script file, its name (found in the tab above it), turned red and got an asterisk placed next to it:
This means our script has unsaved changes. To fix that, go to “File”, then select “Save.” Or, you can hit Control+S on your keyboard, or press the blue “disk” button in the top-left corner of the Script pane (just below the arrowhead in the picture above).
If your script already has a name, doing any of these will save the file. If it doesn’t have a name, you’ll be prompted to give it one as you save it. [R scripts get the file extension “.R” to indicate that they are “special.”]
Callout
One of programming’s cardinal rules is “save often!” Your script file is only a permanent record of your work if you remember to save your work regularly!
Challenge
Scripts may permanently save your code, but not everything in a script needs to be code!
Type and run the following from a script : #2 + 5.
What happens in the Console? What does this teach us?
In this case, R will print your command in the Console, but it won’t
produce any output. That is because # is
R’s comment operator. A comment is anything that
follows a # in the same coding “line.” When R encounters
a comment while executing code, it skips it.
This means that you can leave yourself notes that R will ignore, even if they are interspersed between functional commands!
Callout
Writing comments explaining your code (what it’s for, how it works, what it requires, etc.) is called annotating. Annotating code is a really good idea! It helps you (and others) understand your code, which is particularly valuable when you’re still learning. As we proceed through these lessons, we highly recommend you leave yourself as many helpful comments as you can—it’ll make your script a learning resource in addition to a permanent record!
(Section #2) Objects of our affection
At this point, we know several fundamental R concepts:
Spaces don’t (generally) matter (except that they make code easier for us humans to read).
Line breaks (made with the enter key) do matter (if they make a command incomplete).
Commands can be complete or incomplete, just like sentences can be complete or incomplete. If we try to execute an incomplete command, R expects us to finish it before it’ll move on.
R has a number of symbols (operators) with particular meanings, such as
#and*.R will ignore comments (anything on a line following a
#), and annotating our code with comments is good.Writing code in scripts is also good.
We’ve taken our first steps towards R fluency! But, just as it would be for a human language, the next step is a big one: We need to start learning R’s nouns.
Assignment and our environment
In your script, run 5 [Note: besides hitting the “Run”
button, you can press control/command+enter on your keyboard to run
commands from a script].
R
5
OUTPUT
[1] 5R just repeats 5 back. Why? Because we didn’t tell R to
do anything with 5; it could only assume we wanted
5 returned as a result.
Important: This is, in a nutshell, how our
relationship with R works—it assumes we are giving
commands (“orders”) for which we’ll provide
inputs R should use to carry out those “orders” (in
this case, our input was 5). R will then execute
those commands by doing some work and returning some
outputs (in this case, the output was also
5).
In broad strokes, any single input we give R, or any single output we receive from R, is a “noun” in the R language—these nouns are called objects (or, sometimes, variables).
The 5s we’ve just seen are “temporary,” or
unnamed, objects. They exist only as long as it takes R to work
with or yield them, after which R promptly forgets they exist (it’s like
R has extreme short-term memory loss!).
However, if we don’t want R to forget a noun, we can prevent it. In your script, run the following:
R
x = 5
What happens in the Console when this command runs? Do you notice anything different or new in your RStudio window?
At first, it might seem like nothing’s happened; R reports our command in the Console but no outputs, just like when we ran a comment.
However, find the pane labeled “Environment” (it’s most likely in the upper-right, though it could be somewhere else). Once you’ve found it, if it says “Grid” in the top-right corner, good! If it says “List” instead, click that button and switch it to “Grid.”
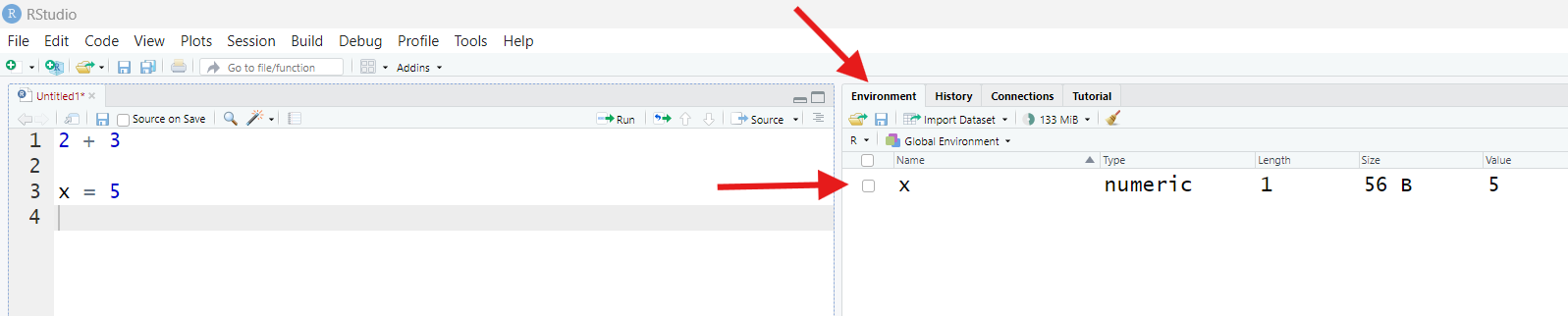
Before now, this pane may have said “Environment is empty.” Now, it
should instead list something with the Name x, a Value of
5, a Length of 1, and a Type of
numeric.
What’s happened? Let’s experiment! In your script, run:
R
x + 4
R will return:
OUTPUT
[1] 9This is interesting. In English, adding 4 to a letter is
non-sensical. However, R not only does it (under these circumstances,
anyway!), but we get a specific answer back. It’s as if R now knows,
when it sees x, that what it should think
is 5.
That’s because that’s exactly what’s happening! Earlier, with our
x = 5 command, we effectively taught R a new “word,”
x, by assigning a value of 5
to a new object by that name (= is R’s
assignment operator). Now, whenever R sees
x, it will swap it out for 5 before doing any
operations.
x is called a named object. When we
create named objects, they go into our Global
Environment (or “environment” for short). To understand what
our environment is, imagine that, when you start up R, it puts
you inside a completely empty room.
As we create or load objects and assign them names, R will start filling this room with bins and shelves and crates full of stuff, each labeled with the names we gave those things when we had R create them. R can then use those labels to find the stuff we’re referencing when we use those names.
At any time, we can view this “room” and all the named objects in it: That’s what the Environment pane does.
Once we have named an object, that object will exist in our Environment and will be recognized by R as a “word” until we either:
Remove it, which we could do using the
rm()function (more on functions later) or by using the “clear objects” button in the Environment pane (it looks like a broom).We close R (R erases our environment every time we exit, by default).
The fact that our entire environment is lost every time we close R may sound undesirable (and, when you’re learning, it often is!), but the alternative would be that our “room” (environment) just gets more and more clogged with stuff. That’d create problems too!
Callout
Besides, the point of working in a script is that we can keep all the code we need to remake all our needed named objects, so we should never have to truly “start over from scratch!”
Besides looking at your environment, if you want to see the contents
of a named object (hereafter, we’ll just call these “objects”), you can
have R show you its contents by asking R to print that object.
You can do this using the print() function or simply by
executing only the object’s name as a command:
R
print(x)
OUTPUT
[1] 5R
x
OUTPUT
[1] 5Naming an object may not seem like much of a “feature” to you now
(it’s not like 5 is harder to type than x!),
but an entire 30,000 row data set could also be a single object
in R. Imagine typing that whole thing out every time you want to
reference it! So, being able to give an input/output, no matter its size
or complexity, a brief “nickname” is actually very handy.
Naming rules and conventions
Let’s talk about the process of naming objects (assignment) in more detail.
In your script, type the following, but don’t execute it just yet:
R
y = 8 + 5
Guess what R will do when you provide it with this command. Then, execute the command and see if you were right!
You should see y appear in your environment. What
“Value” does it have? Is that what you thought it would be?
R
y = 8 + 5
y
OUTPUT
[1] 13We get back a Value of 13 for y. What this
tells us is that, when R executed our command, it did so in a particular
way:
It first did the stuff we’ve asked it to do on the right-hand side of the
=operator (it added two numbers).Then it created an object called
yand stuffed it with the result of that operation. This is why ouryhas a value of13and not8 + 5.
This may seem strange, but, at least for assignment, R kind of reads right to left in that it assumes we want to store the result of operations inside objects, not the operations themselves. As we’ll see, this is not the only way that R reads a command differently than you or I might read text.
Time for our next experiment. Execute the following command:
R
y = 100
What happens, according to your Environment pane? Is that what you expected to happen?
If you look in your environment, there will still be one (and only
one) object named y, but it’s Value will have changed to
100. This demonstrates two things about how assignment
works in R:
Object names in R must be unique—you can have only one object by a specific name at a time.
If you try to create a new object using an existing object’s name, you will overwrite the first object with the second; the first will be permanently lost!
This is why it’s really important to pick good names for your objects—more on that in a second.
Next, type and run the following:
R
Y = 47
What does the Environment pane report now? Is that what you expected?
You should see an object called Y appear in your
environment. Meanwhile, y is also there, and it’s value
hasn’t changed. What gives—didn’t we just establish that names
had to be unique??
Well, they do! But R is a case-sensitive programming language.
This means that, to R, Y is different from y.
So, Y and y are completely different “words,”
as far as R is concerned!
Callout
For beginning programmers, forgetting about case sensitivity is the number-one source of errors and frustration! If you learn absolutely nothing else from these lessons, learn that you can’t be “casual” about upper- versus lowercase letters when you are coding!
Let’s continue experimenting. Run the following two commands:
What happens? What does this experiment teach us?
The first command runs fine—we get a new object named z1
in our environment. This teaches us that including numbers in object
names in R is ok.
I am error
However, the second command does not result in a new object
called 1z. Instead, R returns an error
message in the Console. Uh oh! Error messages are R’s way of saying
that we’ve formed an invalid command.
To be completely frank, R’s error messages are generally
profoundly unhelpful when you’re still learning. This one, for
example, says Error: unexpected symbol in "1z" . What the
heck does that even mean?!
Well, to translate, it’s R’s way of saying that while numbers
are allowed in object names, your object names can’t
start with numbers. So, the 1 at the beginning
is an “unexpected symbol.”
When you get error messages in R, you might get frustrated because you will know you did something wrong but you may not be able to figure out what that something was. Just know this will improve with time and experience.
Callout
In the meantime, though, here are two things you should always try when you get an error message and don’t immediately know what your mistake was:
Check for typos. 95% of error messages are R’s cryptic way of saying “I’m not 100% sure that I know which object(s) you’re referring to.” For example, as we saw earlier,
variable1would be a different word thanVariable1or evenvarible1, so start troubleshooting by making sure you didn’t mix up capital and lowercase letters or add or remove characters.Try Googling the exact error message. It’s likely one of the first results will have an explanation of what may cause that particular error. (An even better option these days might be asking a derivative AI program like ChatGPT to explain the error to you, if you also provide the code that caused it!)
Errors are an inevitable consequence of coding. Don’t fear them; try to learn from them!
As you use R, you will also encounter warnings. Warnings are also messages that R prints in the Console when you run certain commands. It’s important to stress, though, that warnings are not errors. An error means R knew it couldn’t perform the operation you asked for, so it gave up; a warning means R did perform an operation, but it’s unsure if it did the right one, and it wants you to check.
A quick way to see a warning is to try “illogical math,” like logging a negative number:
R
log(-1)
WARNING
Warning in log(-1): NaNs producedOUTPUT
[1] NaNHere, R did something, but it might not have been the
something we wanted [NaN is a special value
meaning “not a number,” which is R’s way of saying “the math you just
had me do doesn’t really make sense!”].
The line between commands so invalid that they produce errors and commands just not invalid enough to produce warnings is thin, so you’re likely to encounter both fairly often.
Going back to our “room”
Anyhow, let’s return to objects: Try the following commands:
What happens? What does this teach us?
The first command runs fine; we see object_1 appear in
our environment. This tells us that some symbols are allowed in
R object names. Specifically, the two allowable symbols are
underscores _ and periods ..
The second command returns an error, though. This tells us that spaces are not allowed in R object names.
Here’s one last experiment—Type out the following commands, consider what each one will do, then execute them:
R
x = 10
y = 2
z = x * y
y = -1000
z
OUTPUT
[1] 20What is z’s Value once these commands have run? What did
you expect its Value to be? What does this teach us?
Here, we created an object called z in the third command
by using two other objects, x and y in the
assignment command. We then overwrote the previous
y’s Value with a new one of -1000. However,
z still equals 20, which is what it was before
we overwrote y.
This example shows us that, in R, making objects using other
objects doesn’t “link” those objects. Just because
we made z using y doesn’t mean z
and y are now “linked” and z will
automatically change when y does. If we change
y and want z to change too, we have to
re-run any commands used to create z.
This is actually a super important R programming concept: R’s objects never change unless you run a command that explicitly changes them. If you want an R object to “update,” a command must trigger that!
It’s natural to think as though computers will know what we want and automate certain tasks, like updating objects, for us, but R is actually quite “lazy.” It only does exactly what you tell it to do and nothing more, and this is one very good example.
What’s in a name?
We’ve learned how we can/can’t name objects in R. That brings us to how we should/shouldn’t name them.
In programming, it’s good practice to adopt a naming convention. Whenever we name objects, we should do it using a system we use every single time.
Why? Well, among other reasons, it:
Prevents mistakes—you’ll be less likely to mess up or forget names.
Saves time because coming up with new names will be easier and remembering old names will be faster because they’re predictable.
Makes your code more readable, digestible, and shareable.
Our goal should be to create object names that are unique, descriptive, and not easily confused with one another but, at the same time, aren’t a chore to type or inconsistent with respect to symbols, numbers, letter cases.
So, by this logic, y is a terrible name! It
doesn’t tell us anything about what this object stores, so we’re
very likely to accidentally overwrite it or confuse it with
other objects.
However, rainfall_Amounts_in_centimetersPerYear.2018x is
also a terrible name. Sure, it’s descriptive and unique, and we
wouldn’t easily mix it up with others object, but it’d be a pain to
type! And with the inconsistencies in symbol and capital letter usage,
we’d typo it a lot.
Here are some example rules from a naming convention, so you can see what a better way to do things might look like:
All names consist of 2-3 human “words” (or abbreviations).
All are either in all caps
LIKETHISor all lowercaselikethis, or if capitals are used, they’re only used in specific, predictable circumstances (such as proper nouns).-
Words are separated to make them more readable.
- Some common ways to do this include using so-called snake_case, where words are separated by underscores, dot.case, which is the same using periods, or camelCase, where one capital is used after where a space would have been.
Numbers are used only when they convey meaning (such as to indicate a year), not to “serially number” objects like
data1,data2,data3, etc. (such names are too easy to confuse and aren’t descriptive).Only well-known abbreviations are used, such as
wgtfor “weight.”
Making mistakes in any language is frustrating, but they can be more frustrating when you’re learning a programming language! It may seem like a hassle, but using a naming convention will prevent a lot of frustrating mistakes.
Discussion
Pause and jot down several rules for your own personal naming convention.
There are no “right answers” here. Instead, I’ll give you a couple of rules from my own personal naming convention.
First, generally speaking, column names in data sets are written in ALLCAPS. If I need to separate words, I do so using underscores. My comments are also written in ALL CAPS to make them stand out from the rest of my code.
Meanwhile, I only use numbers at the ends of names, and I never use periods.
Lastly, I use snake_case for function names (more on functions in a bit), but I use camelCase for object names.
One last thing about assignment: R actually has a
second assignment operator, the arrow
<-. If you use the arrow instead of = in an
assignment command, you’ll get the same result! In fact,
<- is the original assignment operator;
= was added recently to make R a bit more like other common
programming languages.
In help documents and tutorials, you will often see
<- because it’s what a lot of long-time R users are used
to. Also, = is used for not one but several other
purposes in R (as we’ll see!), so some beginners find it confusing to
use = for assignment also.
Throughout, these lessons use = for assignment because
it’s faster to type (and what the instructors are used to). However, if
you would prefer to use <-, go for it! Just recognize
that both are out there, and you are likely to encounter both as you
consume more R content.
Just typical
Earlier, when we made x and assigned it a value of
5, R reported its Type as numeric in our
environment. What does “Type” mean?
Computers, when they store objects in their “heads,” have particular ways of doing so, usually based on how detailed the info being stored is and how this info could later be used.
Numeric data (numbers with potential decimals) are quite detailed, and they can be used in math operation. As such, R stores these data in a specific way acknowledging these two facts.
Let’s see some other ways R might store data. In your script, run the following commands, paying close attention to punctuation and capitalization:
R
wordString = "I'm words" #Note the use of camelCase for these object names :)
logicalVal = FALSE
You should get two new objects in your environment. The first should
have a Type of character. This is how R stores text
data.
Discussion
Note we had to wrap our text data in quotes
operators " " in the command above.
Text data must always be quoted in R. Why? What would
happen if we tried to run x = data instead of
x = "data", for example?
As we have seen, R thinks unquoted text represents a potential object name. So, to make it clear that we are writing textual data and not an object name, we quote the text.
In our hypothetical example, if we tried to run
x = "data", we’d store the value of "data" in
an object called x. If, instead, we ran
x = data, R would look for an object called
data to work with instead. If such an object exists, its
current value inside a second object called x. But, if no
such object existed, R would instead return an error, saying it couldn’t
find an object named data.
Forgetting to quote text is an extremely common mistake when learning R, so pay close attention to the contexts in which quotes are used in these lessons!
Text data can also be detailed (a whole book could be a single text object!) but they can’t be used for math, so it makes sense R uses a different Type to store such data.
The second object above (logicalVal) has a Type of
logical. Logical data are “Yes/No” data. Instead of storing
these data as “Yes” or “No,” though, a computer stores them as
TRUE or FALSE (or, behind the scenes, as
1 or 0). These data are not detailed compared
to others we’ve seen, so it makes sense there’s another type for storing
them. We’ll see what logical data are for in a later section.
You can think of types as R’s “adjectives:” They describe what kinds of objects we’re working with and what can and can’t be done with them.
There are several more object Types we’ll meet, but before we can, we need to take our next big step: we need to learn about R’s verbs.
(Section #3) Function junction
Earlier, we established that our relationship with R is one in which we provide R with inputs (objects) and commands (“orders”) and it responds by doing things (operations) and producing outputs (more objects). But how does R “do things?”
Just as with a human language, when we’re talking actions, we’re talking verbs. R’s verbs are called functions. Functions are bundles of one (or more) pre-programmed commands R will perform using whatever inputs it’s given.
We’ve actually met an (unusual) R function already: +.
This symbol tells R to add two values (those on either side of it). So,
a command like 2 + 2 is really a bundling together of our
inputs (2 and 2) and an R verb (“add”).
Most R verbs look different from +, though. In your
script, run the following:
R
sum(2, 5)
What did R do? What does this teach us?
We’ve just successfully used sum(), R’s more
conventional, general verb for “add the provided stuff,” and it is a
good example of how functions work in R:
Every function has a name that goes first when we’re trying to use that function.
Then, we add to the name a set of parentheses
( ). [Yes, this is a second, different use of parentheses in R!]Then, any inputs we want that function to use get put inside the parentheses. Here, the inputs were
2and5. Because we wanted to provide two inputs and not just one, we had to separate them into distinct “slots” using commas,.
If we omit or mess up any of those three parts, we might get an unexpected result or even an error! Just like any language, R has firm rules, and if we don’t follow them, we won’t get the outcome we want.
Side-note: In programming, using a function is referred to as
calling it, like it’s a friend you’re calling up on the phone
to ask for a favor. So, the command sum(2, 5) is a
call to the sum() function.
Challenge
As we’ve seen, R is a powerful calculator. As such, it has many math
functions, such as exp(), sqrt(),
abs(), sin(), and round(). Try
each and see what they do!
exp() raises the constant e to the power of
the provided number:
R
exp(3)
OUTPUT
[1] 20.08554sqrt() takes the square root of the provided number:
R
sqrt(65)
OUTPUT
[1] 8.062258abs() determines the absolute value of the provided
number:
R
abs(-64)
OUTPUT
[1] 64sin() calculates the sine of the provided number:
R
sin(80)
OUTPUT
[1] -0.9938887round() rounds the provided number to the nearest whole
number:
R
round(4.24)
OUTPUT
[1] 4Pro-to types
R also has several functions for making objects, including some important object types we haven’t met yet! Run the following command:
R
justANumber = as.integer(42.4)
This command produces an object of Type integer. The
integer type is for numbers that can’t/don’t have decimals, so any data
after the decimal point in the value we provided gets lost, making this
new object’s Value 42, not 42.4.
Next, run:
R
numberSet = c(3, 4, 5)
This produces an object containing three Values (3,
4, and 5) and is of Type numeric,
so it maybe doesn’t look all that special at first.
The product of a c() function call is special
though—this function combine (or
concatenates) individual values into a unified
thing called a vector. A vector is a set of values
grouped together into one object. We can confirm R thinks
numberSet is a vector by running the following:
R
is.vector(numberSet)
OUTPUT
[1] TRUETo which R responds TRUE (which means “Yes”).
If a single value (also called a scalar) is a single point in space (it has “zero dimensions”), then a vector is a line (it has “one dimension)”. In that way, our vector is different from every other object we’ve made until now! That’s important because most R users engage with vectors all the time—they’re one of R’s most-used object types. For example, a single row or column in data set is a vector.
One reason that vectors matter is that many functions in R are vectorized, meaning they operate on every entry inside a vector separately by default
To see what I mean, run the following:
R
numberSet - 3
OUTPUT
[1] 0 1 2What did we receive? What did this teach us?
R returns a vector of the same length as numberSet but
containing 0, 1, and 2, which are
what you’d get if you had subtracted 3 from each entry in
numberSet separately. That’s vectorization! More on that in
a later lesson.
So, most R functions are designed to work not just on lone values but
on vectors, and some even expect their inputs to be vectors. A
good example is mean(), which takes the average of the
provided inputs. Yes, you could take the average of just one
value, but it’d be pretty pointless! So it makes sense this function
expects a vector and not a scalar as an input.
Let’s try it. Run:
R
mean(numberSet)
OUTPUT
[1] 4Vectors can hold non-numeric data too. For example, (carefully) type and run the following:
R
charSet = c("A", "B", "B", "C")
This will create a character vector. If we check our
environment, we will notice it has a Length of 4, due to
its four entries. If you ever want to see the length of a vector, you
can use the length function:
R
length(charSet)
OUTPUT
[1] 4Timeout for factors
We can use charSet to discover another, special R object
Type. Run:
R
factorSet = as.factor(charSet)
If you check your environment after this command, you’ll see we’ve
made an object of Type factor. What’s a factor??
Factors are a special way R can store categorical data (data that belong to different, discrete categories that cannot be represented meaningfully with numbers, such as “male”, “female”, and “neuter”).
To create a factor, R:
Finds all the unique categories (here, that’s
A,B, andC).Picks a “first” category. By default, it does this alphanumerically, so
Ais “first.”It turns each category, starting with the first, into a “level,” and it swaps that category out for an integer starting at
1. So,Abecomes level1,Bbecomes level2, and so on.
This means that, under the hood, R is actually now storing these text data as numbers and not as text. However, it also stores which categories goes with which numbers. That way, at any time, it can “translate” between the numbers it’s storing and the text values in the original data. So, whenever it makes sense to treat these data as text, R can do that, and whenever it’d be easier for them to be “numbers” (such as when making a graph), R can do that too!
We can see all this underlying structure using the structure
function, str():
R
str(factorSet)
OUTPUT
Factor w/ 3 levels "A","B","C": 1 2 2 3This will show that R now thinks of our A, B, B, C data
as 1, 2, 2, 3, but it hasn’t forgotten that 2
really means B.
For certain operations, factors are very convenient. Part of why R became so beloved by statisticians was because of factors!
However, if you think factors are weird, you’re right—they are. If you don’t want to use them, increasingly, you don’t have to; they are sort of falling out of favor these days, truth be told. But they are still common enough that it pays to be aware of them.
2D or not 2D
Moving on, we have another two important objects to meet: Matrices and data frames. Type (carefully) and run the following:
R
smallMatrix = matrix(c(1, 2, "3", "4"))
This command demonstrates another fundamental concept: In R, you can stuff functions calls inside other function calls. This is called nesting.
When we nest, R reads our command from the “inside out,”
evaluating inner operations first before tackling outer ones. So, here,
R first creates a vector containing the values 1,
2, "3", and "4". It then
provides that vector to the matrix() function, which
expects to be given a vector of values it can arrange into a matrix
format.
As such, we don’t have to stop and name every object we want to use—we can choose to use or create unnamed objects if that’s our preference.
However, for many beginners, reading nested code can be tricky, and not saving “intermediate objects” feels wrong! If you’d prefer, you can always write commands one at a time rather than nest them; it’ll take more time and space, but you might find it more readable. For example, here, you could have instead done something like this:
R
smallMatrixVec = c(1, 2, "3", "4")
smallMatrix = matrix(smallMatrixVec)
Anyhow, we can see our matrix by running just its name as a command. When we do that, we see this:
R
smallMatrix
OUTPUT
[,1]
[1,] "1"
[2,] "2"
[3,] "3"
[4,] "4" If a vector is a one-dimensional set of values, then a matrix is a
two-dimensional set of values, arranged in rows and columns. Here,
we created a matrix with one column (marked at the top with
[,1]) and four rows (marked along the left side with
[1,], [2,], and so on).
Discussion
Notice that all values in our matrix are now text (they are
surrounded by "s), even the 1 and
2 we originally entered as numbers. Why do you think this
happens?
Vectors and matrices (most objects, really!) in R can only hold values of a single Type. If we try to put multiple value types into one object, R will change (or coerce) the more complex/versatile type(s) into the simpler/less versatile type(s). In this case, it turned our numeric data (which can be used for math) into character data (which can’t be used for math).
Why does R coerce dara? Well, remember—many operations in R are
vectorized, meaning they happen to all values in an
object simultaneously and separately. This means we could run a command
like smallMatrix + 4 to try to add 4 to
all values in our matrix. This would make sense for our numbers
but not for our text!
Rather than giving us the opportunity to make mistakes like that, R “reduces” all values in an object to the “simplest” available type so that we never try to do “more” with an object’s values than we should be able to.
So data coercion makes sense, when you think about it. However, what if you have a data set that contains both text and numeric data? R has you covered, so long as those data are in different columns! Run the following:
R
smallDF = data.frame(c(1,2), c("3", "4"))
Follow this with smallDF as a command to see the
result:
R
smallDF
OUTPUT
c.1..2. c..3....4..
1 1 3
2 2 4This time, we get an object of Type data.frame. Data
frames are another special R object type! Like a matrix, a data frame
is a 2D arrangement of values, with rows and columns (albeit marked
differently than those in our matrix).
However, this time, when we look at our new data frame in the Console, it looks like R has done the opposite—it looks like it has turned our text into numbers!
But, actually, it hasn’t. To prove it, we can use the structure
function, str(), to look under the hood at
smallDF. Type and run the following:
R
str(smallDF)
OUTPUT
'data.frame': 2 obs. of 2 variables:
$ c.1..2. : num 1 2
$ c..3....4..: chr "3" "4"You should get output like this:
OUTPUT
'data.frame': 2 obs. of 2 variables:
$ c.1..2. : num 1 2
$ c..3....4..: chr "3" "4"On the left-hand side of the output is a list of all the columns in our data frame and their names (they’re weird here because of how we made our data frame!).
On the right-hand side is a list of the Types of each column and the
first few values in each one. Here, we see that, actually, the second is
still of Type character (“chr” for short). The quotes
operators just don’t print when we look at a data frame.
The str() output shows that we have, in the same object,
two columns with different data types. It’s this property that makes
data frames special, and it’s why most R users engage with data frames
all the time—they are the default object type for storing data sets.
Note that every column can still only contain a single data type, so you can’t mix text and numbers in the same column without coercion happening.
Another object type R users encounter often is lists. Lists are useful but also weird; we’re not going to cover them here, but, if you’re curious, you can check out this resource to become better acquainted with them. There are also objects that can hold data in 3 (or more) dimensions, called arrays, but we won’t cover them here either because most users won’t need to use them much, if ever.
For argument’s sake
Earlier, we saw that functions get inputs inside their parentheses
( ) and, if we are giving a function multiple inputs, we
separate them using commas ,. This helps R know when one
input ends and another begins.
You can think of these commas as creating “slots,” with each slot receiving one input. These “slots” may feel like things we, the users, create as we call functions, but they actually aren’t!
When a programmer creates a function, they need to ensure that the user knows what inputs they are expected to provide (so we’re not providing illogical types of inputs or an inadequate number of them). Meanwhile, R needs to know what it’s supposed to do with those inputs, so it needs to be able to keep them straight.
The programmer solves these two programs by designing each function to have a certain number of input slots (these are called parameters). Each slot is meant to receive an input (formally called an argument) of a particular type, and each slot has its own name so R knows which slot is which.
…This’ll make much more sense with an example! Let’s consider
round() again. Run the following:
R
round(4.243)
OUTPUT
[1] 4We get back 4, which tells us that round()
rounds our input to the nearest whole number by default. But what if we
didn’t want to round quite so much? Could we round to the nearest tenth
instead?
Well, round(), like most R functions, has more than one
input slot (parameter); we can give it not only numbers for it
to round but instructions on how to do that.
round()’s first parameter (named x) is the
slot for the number(s) to be rounded—that’s the slot we’ve already been
providing inputs to. Its second parameter slot (named
digits), meanwhile, can receive a number of decimal places
to round those other inputs to.
By default, digits is set to 0
(i.e., don’t round to any decimal place; just give back whole
numbers). However, we can change that default if we want. Run the
following:
R
round(4.243, 1)
OUTPUT
[1] 4.2By placing a 1 in that second input slot, we’ve asked R
to round our first input to the nearest tenth instead.
Challenge
We can learn more about how functions work with some experiments. Type the following into your script, but don’t run it yet:
R
round(1, 4.243)
This is the exact same inputs we gave round() before,
just reversed. Do you think R will generate the same output? Why or why
not? Try it and observe what you get.
R
round(1, 4.243)
OUTPUT
[1] 1You get back 1, which is not the same answer as we got
before. Why?
We essentially just asked R to round 1 to
4.243 decimal places. Since that doesn’t really make sense,
R assumes we meant “round to 4 decimal places.” However, since
1 is already fully rounded, there’s no need to round it
further.
The experiment in the exercise above shows that, for R functions, input order matters. That is, specific slots are in specific places inside a function’s parentheses, and you can’t just put inputs into slots all willy-nilly!
…Or maybe you can, if you’re a little more thoughtful about it. Try this instead:
R
round(digits = 1, x = 4.243)
This time, you should get back 4.2, like we did the
first time.
OUTPUT
[1] 4.2This is because we have used the parameter names (to the left of the
=s) to match up our inputs (to the right of the
=s) with the specific slots we want them to go into. Even
though we provided the inputs in the “wrong” order, as far as how
round() was programmed, we gave R enough information that
it could reorder our inputs for us before doing continuing.
When in doubt, always “name” your arguments (inputs) in this way, and you’ll never have to worry about specifying them in the wrong order!
Note—we’ve just seen a second use for the = operator.
Until now, we’ve only used = to create new named
objects (assignment). Here, we’re matching up
inputs with input slots (we’re naming our
arguments). In both cases, names are involved, but, in
the latter, nothing new is actually being created or added to R’s
vocabulary.
Challenge
I mentioned that some folks find it confusing that = has
multiple different uses. Let’s see if you might be one of those people.
Consider the following command:
R
newVar = round(x = 4.243, digits = 4)
Can you explain what this command does?
First off, we could have written this same command this way instead:
R
newVar <- round(x = 4.243, digits = 4)
We’re asking R to create a new named object called
newVar; that new object will contain the result of a
call to round(). This assignment task is
facilitated by the = operator (but could just as easily
have been facilitated by the <- operator).
For our round() call, we’ve provided two inputs, an
x (a value to round) and a number of digits to
round that value to. We’ve ensured R knows which input is which by
naming the slots we want each to go into. This input-slot matching is
facilitated by the = operator also (the <-
operator would NOT work for this purpose).
If it feels harder to read and understand commands that use the same
operator (=) for two different purposes, that’s ok! Just
switch to <- for assignment.
Notice that we can call round() with or without
giving it anything for its digits parameter. It’s
as though that slot is “optional.”
That’s because it is! Some input slots have default values their designers gave them. If we’re ok with those defaults, we don’t need to mess with their slots at all. Many optional inputs are there if you want to tweak how R performs a more basic operation. In that way, they are kind of like R’s adverbs, if you think about it!
By contrast, try this command:
R
round(digits = 1)
You’ll get an error. What is this error telling us?
The error will say
Error: argument "x" is missing, with no default. This is
actually a pretty informative error, for a change! We know, now, that
the number(s) we want to round go in a slot named x. In the
example above, we know we didn’t provide any inputs for x,
so our x input is indeed “missing.”
It makes sense this would be a problem—understandably,
round() has no default for x. How could it?
Are we expecting R to somehow guess what value(s) we are hoping to
round, out of all possible values?? That would be an
insane expectation!
So, while some function inputs might be optional, others are required because they have no defaults. If you try to call a function without specifying all required inputs, you’ll usually get an error.
Next, let’s try this command:
R
round(x = "Yay!")
This will also trigger an error, with another error message you should hopefully be able to decode!
The error says
Error in round: non-numeric argument to mathematical function.
Basically, it’s saying “Hey! You just tried to get me to do math on
something that is clearly not a number!”
This shows that each input probably needs to be of a specific form or Type so that a function’s operations are more likely to work as planned.
Getting help
By this point, you might be wondering: “But how would I know what input slots a function has? Or what types or forms of inputs I should be providing? Or what what those slots are named? Or what order those slots are in? Or which slots are required?”
These are all super good questions! Thankfully, there’s an easy answer to them all—we can look them up! Run the following command:
R
?round #You can run this with or without ()s
This command should trigger your RStudio to show its Help pane, generally found in the bottom-right corner (though it could be somewhere else).
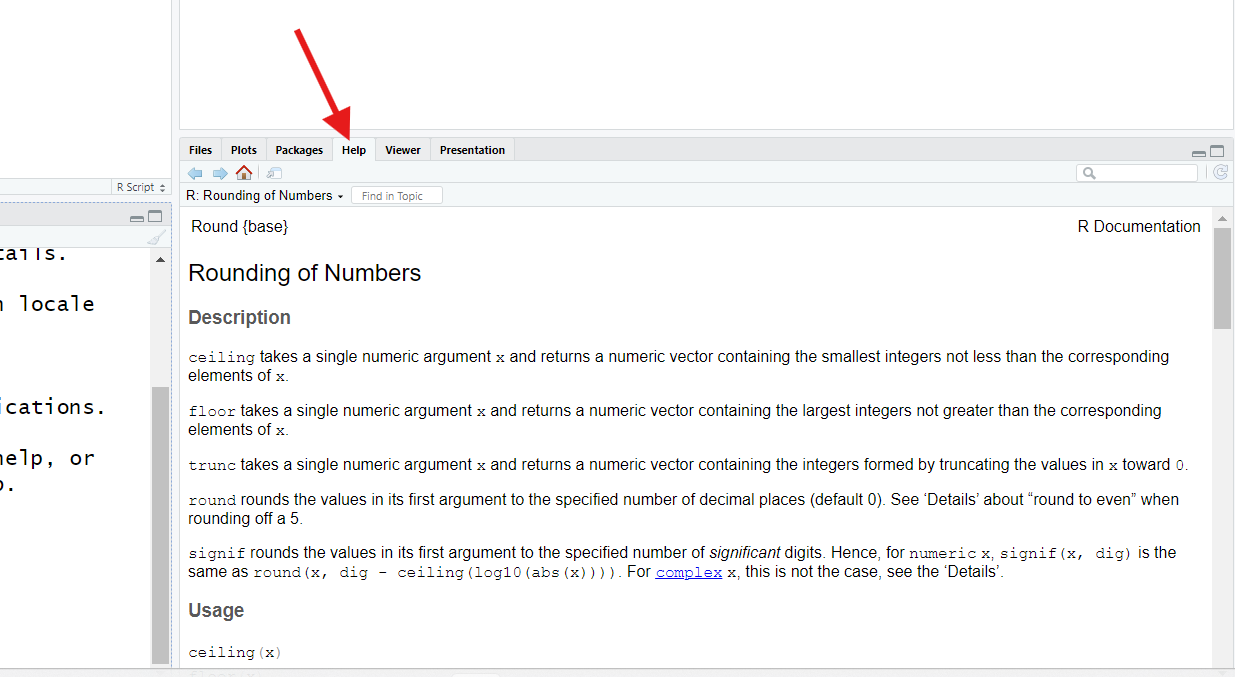
The ? operator, when used in front of a function’s name,
will bring up the help page for that function.
Fair warning: These are not always the easiest pages to read! In general, they are pages written by programmers for programmers, and it shows.
However, already, you might discover you understand more of this page’s contents than might think. Here’s what to look for when reading a function’s help page:
The function’s name is at the top, along with the name of the package it’s from in braces
{ }.roundis in thebasepackage, which means it comes with “base R.”The
Descriptionsection describes (hopefully clearly!) what the function’s purpose is, generally. If a number of related functions can logically share the same help page (as is the case here), those other functions will be listed and described here too.The
UsageandArgumentssections show the input slots for this function, their names, and the order they’re expected in. You should see, in theUsagesection, thatxanddigitsare the first and second inputs forround().In the
Argumentssection, you can read more about what each input slot is for (they are also listed in order). If there are any form or type requirements for an input, those will (hopefully) be noted here.The
Detailssection is one you can generally skip; it typically holds technical details and discusses quirky edge cases. But, if a function seems to be misbehaving, it’s possibleDetailswill explain why.At the bottom, the
Examplessection shows some code you could run to see a function in action. These are often technical in nature, but they are sometimes fun. For example, you might find it interesting to consider the first example listed forround(). See if you can guess why it produces the results it does!
A function’s help page should hopefully contain all the answers to your questions and more, if it’s written well. It just might take practice to extract those answers successfully.
…But, if you’re starting out, how would you even know what functions exist? That’s a good question! One without a single, easy answer, but here are some ideas to get you started:
If you have a goal, search online for an example of how someone else has accomplished a similar goal. When you find an example, note which functions were used (you should be able to recognize them now!).
You can also search online for a Cheat Sheet for a given package or task in R. Many fantastic Cheat Sheets exist, including this one for base R, which covers everything this lesson also covers (and more!), so it’ll be a great resource for you.
Vignettes are pre-built examples and workflows that come with R packages. You can browse all the Vignettes available for packages you’ve installed using the
browseVignettes()function.You can use the
help.search()function to look for a specific keyword across all help pages of all functions your R installation currently has. For example,help.search("rounding of numbers")will bring up a list that includes the help page forceiling(), which sharesround()’s help page. You may need to try several different search terms to find exactly what you are looking for, though.
(Section #4) Preparing for takeoff
By this point, we’ve covered many of the basics of R’s verbs, nouns, adverbs, rules, and punctuation! You have almost all the knowledge you need to level up your R skills. This last section covers the last few ideas, in rapid-fire fashion, we think you’ll want to know if you plan to use R regularly.
Missing out
By now, we know almost everything we need to know about functions. However, for the next concept, we need a toy object to work with that has a specific characteristic. Run the following:
R
testVector = c(1, 8, 10, NA) #Make sure to type this exactly!
NA is a special value in R, like TRUE and
FALSE and NaN. It means “not applicable,”
which is a fancy way of saying “this data point is missing and
we’re not sure what it’s value really is.”
When we load data sets into R, any empty cells will automatically get
filled with NAs, and NAs get created in many
other ways beyond that, so regular R users encounter NA a
lot.
Let’s see what happens when we encounter NA in the
course of doing other work. Run:
R
mean(testVector)
The mean() function should return the average (mean) of
a set of numbers. What’s it return when used on
testVector?
OUTPUT
[1] NAHmm. It returns NA. This actually makes sense, if you
think about it. R was asked to take the mean of a set of values that
includes a value that essentially is “who even knows?” That’s a pretty
insane request on our part!
Additionally, R might wonder if you even know you’re missing data. By
returning NA, R lets us know both that you’re missing data
and that it doesn’t know how to do what you’ve asked.
But what if you did know you were missing data and you just wanted R to calculate the average of the non-missing data you provided?
Maybe there’s an optional parameter for that? Let’s check by pulling
up mean()’s help page:
R
?mean
When we do, we discover that mean() has an optional
input, na.rm, that defaults to FALSE, which
means “don’t remove (rm) NAs when going to calculate a
mean.”
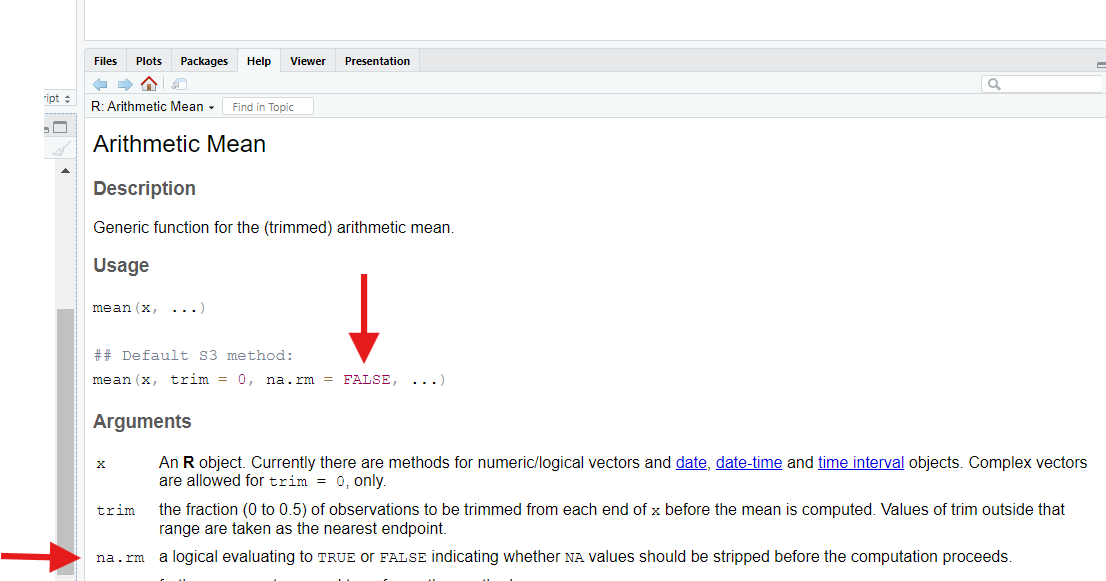
If we set this parameter to TRUE, mean()
will do what we want—it will strip out NAs before
trying calculating the average.
Challenge
However, if we try to do that like this, we get an error:
R
mean(testVector, TRUE)
Why doesn’t that command work?
We get an error that discusses trim. What even is
that?!
If we re-consult the function’s help page, we might discover that,
actually, mean() has three input slots, and
na.rm is the third one; the second one is
named trim.
Because we only provided two inputs to mean(), R assumed
we wanted those two inputs to go into the first two input
slots. So, we provided our na.rm input to the
trim parameter by mistake!
To avoid this, we could provide a suitable value for
trim also, such as it’s default value of 0,
like this:
R
mean(testVector, 0, TRUE)
This works, but we could also just match up our inputs with their target slots using the slots’ names, as we learned to do earlier:
R
mean(x = testVector, na.rm = TRUE)
Doing this allows us to skip over trim entirely (since
it’s an optional input)! That makes this approach easier.
Callout
This is another good reason to always name your function inputs. Some functions have dozens of input slots. If you only want to engage with the last few, e.g., using the parameter names to match up your inputs with those slots is the only sensible option!
Sequences
One thing regular R users find themselves needing to make surprisingly often is a sequence, which is a vector containing values in a specific pattern.
If we just want a simple sequence, from some number
to some number counting by one, we can use the :
operator:
R
-3:7
OUTPUT
[1] -3 -2 -1 0 1 2 3 4 5 6 7If we want to repeat a value multiple times, we can use the
rep() function:
R
rep(x = 3, times = 5)
OUTPUT
[1] 3 3 3 3 3rep() can also be used to repeat entire vectors of
values:
R
rep(x = -3:7, times = 5)
OUTPUT
[1] -3 -2 -1 0 1 2 3 4 5 6 7 -3 -2 -1 0 1 2 3 4 5 6 7 -3 -2 -1
[26] 0 1 2 3 4 5 6 7 -3 -2 -1 0 1 2 3 4 5 6 7 -3 -2 -1 0 1 2
[51] 3 4 5 6 7If we want to create a more complicated sequence, we can use the
seq() function:
Challenge
Both rep() and seq() have interesting
optional parameters to play with!
For example, what happens if you provide a vector (such as
c(1, 5)) to rep() for x? What
happens if you swap each in for times in the
command rep(x = -3:7, times = 5)? What happens if you swap
length.out in for by in the command
seq(from = 8, to = 438, by = 52)? Try it and see!
If we switch to each instead of times, we
instead repeat each value inside our vector that many times
before moving on to the next value:
R
rep(x = c(1,5), each = 5)
OUTPUT
[1] 1 1 1 1 1 5 5 5 5 5For seq(), when we specify a by, we are
telling R how large the step length should be between each new entry.
When our next entry would go past our to value, R stops
making new entries.
When we switch to using length.out, we tell R to instead
divide the gap between our from and our to
into that many slices and find the exact values needed to
divide up that gap evenly:
R
seq(from = 100, to = 150, length.out = 12)
OUTPUT
[1] 100.0000 104.5455 109.0909 113.6364 118.1818 122.7273 127.2727 131.8182
[9] 136.3636 140.9091 145.4545 150.0000This results in an equally spaced sequence, but the numbers may be
decimals. Using by, however, may cause our last interval to
be shorter than all others, if we hit our to value before
we hit our by value again.
Logical tests
Just like a human language, R has question sentences. We call such commands logical tests (or logical comparisons). For example, run:
R
x = 5 # Create x and set its value
x == 5 #Is x *exactly* equal to 5?
OUTPUT
[1] TRUEAbove, we create an object called x and set its value to
5. We then ask R, using the logical
operator ==, if x is “exactly equal”
to 5? It responds with yes (TRUE), which we
know is correct.
[Yes, this a third, distinct use for the = symbol in R
(although, here, we have to use two; one won’t
work!).]
There are other logical operators we can use to ask different or more complicated questions. Let’s create a more interesting object to use them on:
R
logicVec = c(-100, 0.1, 0, 50.5, 2000)
Challenge
Then, try each of the commands below, one at a time. Based on the answers you receive, what questions do you think we’ve asked?
R
logicVec != 0
logicVec > 0.1
logicVec <= 50.5
logicVec %in% c(-100, 2000)
First, let’s see the answers we receive:
R
logicVec != 0
OUTPUT
[1] TRUE TRUE FALSE TRUE TRUER
logicVec > 0.1
OUTPUT
[1] FALSE FALSE FALSE TRUE TRUER
logicVec <= 50.5
OUTPUT
[1] TRUE TRUE TRUE TRUE FALSER
logicVec %in% c(-100, 2000)
OUTPUT
[1] TRUE FALSE FALSE FALSE TRUEAs you can see, logical tests are vectorized, meaning we compare each entry in our vector separately to the value(s) provided in the question, to the right of the logical operator.
For the first test of logicVec != 0, we get back only
one FALSE, for the third entry. Why? Well, that’s the only
entry whose value is exactly 0. If == is the
logical operator for “is equal to,” !=
must be the logical operator for “is not equal
to.”
For the second test of logicVec > 0.1, we get back
four TRUEs. This one hopefully makes intuitive sense; we’ve
asked which values are strictly greater than 0.1,
and since all but -100 are, we get four “yeses.”
For the third test of logicVec <= 50.5, we get back
four “yeses” as well because four values are either less than
(<) or equal to (=) a value of
50.5.
As you might guess, < and >= are also
logical operators; we just didn’t use them in these
examples!
The last example is a bit weirder. The %in%
logical operator is also called the match
operator. It asks “is each thing on the left also found in the
thing on the right?” That is, it is looking for matches between the left
and right inputs and, when it finds a match, we get TRUE.
“Is each thing on the left equal to anything on the
right?”
Here, we get back two matches, for the first and last entries in
logicVec, which makes sense because -100 and
2000 are indeed found in both vectors we’ve provided.
We can also ask R “multi-part” questions. For example, type and run the following:
R
logicVec > 0 & logicVec < 50
The & operator is the “and” logical
operator. So, here, we’ve asked R two questions that
must both be true for a value to get back a “yes.” Only two of our five
entries satisfy both questions we’ve posed, so we get back two
TRUEs.
Note that both questions need to be complete commands! You
can’t write, for example, just
logicVec > 0 & < 50, even though this would seem
both sensible and tempting.
Also, note that there is an operator for “or”: |. That’s
the “pipe” character, located over by your enter/return key. If you
connect two logical tests with |, so long
as either test passes for an entry, that entry will return
TRUE.
It may not be immediately clear what logical tests are good for, but we’ll see several use cases for them in later lessons.
Subsetting and indexing
We’ve seen both 1D (vectors) and 2D (matrices and data frames) objects, which contain more than one value and might contain millions! If these objects are big enough, printing them to the Console to see their contents would be impractical. How can we carefully and targetedly “look inside” an object?
We can use indexing. This is using a label (e.g., a column name) or index value (e.g., a row number) to “target” a specific value (or multiple values) inside an object.
For example, if we want to see just the first value inside
of the logicVec vector we built earlier, we could do
this:
R
logicVec[1]
OUTPUT
[1] -100The indexing operators, the square brackets [ ], are
keys you might not often use. If it helps you to remember what they’re
for, remember that they look like little “iron sights” you use to “aim”
at specific entries inside objects!
In the command above, we placed the index value 1 inside
our brackets and attached those brackets to the object we wanted to peer
inside.
An index value of 1 will ask R to retrieve the first
value. Logically, if we used an index value of 4 instead,
we’d get back the fourth entry:
R
logicVec[4]
OUTPUT
[1] 50.5Challenge
What happens if we use index values that make less sense? What if we ask for the 8th value, even there is no 8th entry? What if we ask for the “0th” entry? What if we ask for a “negative” entry? Run the following commands to find out:
R
logicVec[8]
OUTPUT
[1] NAR
logicVec[0]
OUTPUT
numeric(0)R
logicVec[-3]
OUTPUT
[1] -100.0 0.1 50.5 2000.0Each of these commands teaches us something different about how indexing works in R.
In the first, we ask for a non-existent 8th entry. R does
not respond with an error or
warning, as we might expect. Instead, it responds
NA. Essentially, it responds as though an 8th entry
could exist; it just doesn’t know what it’s value
would be because that value is currently missing (which could
technically be true). We mentioned earlier that many operations
produce NAs; this is one.
In the second command, we ask for a non-sensical “0th” entry. Again,
R does not respond with an error or warning. Instead, it
responds with a strange value: numeric(0). This is R’s way
of saying “your result is a numeric vector with 0
contents.” Uh…sure!
What’s important here is that this command proves R is different than many other programming languages. In Python, for example, asking for the zeroth entry is actually how you ask for the first entry—Python is a zero-indexed language, which means it starts counting positions at 0 instead of at 1. Row 0 is the first row!
Meanwhile, R is a one-indexed language—if you want the first
row or entry, you use an index value of 1, not
0. Even though that’s probably more intuitive, R is
actually uncommon; most common languages are zero-indexed.
In the third command, we ask for the “negative third entry.” We get
back every entry but the third. That’s because the
- operator, when used in indexing, excludes values at
certain positions rather than targeting them.
You can also use sequences as index values, if you want to peek at multiple values inside an object. Run the following commands to see two examples:
R
logicVec[2:4] #2nd thru 4th values
OUTPUT
[1] 0.1 0.0 50.5R
logicVec[c(1, 5)] #The first and fifth value.
OUTPUT
[1] -100 2000Indexing allows us to peek at specific values inside an object; what if we don’t like the values we see when we do that?
For example, in the testVector object we made earlier,
the fourth entry is NA, which caused problems. We can
combine indexing with assignment to
overwrite (replace) values inside objects. Here’s how
we’d replace that NA with 100:
R
testVector[4] = 100 #Replace the 4th value in testVector with 100.
testVector
OUTPUT
[1] 1 8 10 100If you provide an equal number of replacement values, you can replace multiple values at once:
R
testVector[c(2,4)] = c(-5, 32) #If indexing two values, must provide two replacements.
testVector
OUTPUT
[1] 1 -5 10 32What if we want to have a smaller object than the one we currently
have? We can also combine indexing and
assignment to create subsets (smaller
versions) of an object. Here’s how we’d create a new object containing
just the first and third entries of logicVec:
R
newVec = logicVec[c(1,3)]
newVec
OUTPUT
[1] -100 0This is how indexing works for vectors. It works a little differently with 2D objects. Let’s create a matrix and a data frame to experiment with:
R
mat1 = matrix(4:-4, ncol=3)
df1 = data.frame(x = 1:5, y = letters[1:5])
mat1
OUTPUT
[,1] [,2] [,3]
[1,] 4 1 -2
[2,] 3 0 -3
[3,] 2 -1 -4R
df1
OUTPUT
x y
1 1 a
2 2 b
3 3 c
4 4 d
5 5 eFor vectors, our index values were the positions of the entries we were interested in (position 1, position 2, etc.). Single values make less sense for a 2D object—what’s the 6th position in a 3x3 matrix, for example? Is it the value in the 2nd row and 3rd column? In the 3rd row and 2nd column? Something else? Let’s see what R thinks:
R
mat1[6]
OUTPUT
[1] -1-1 is the value in the 3rd row and 2nd column. Is that
the value you’d have picked? This shows us that R reads (and fills)
matrices top to bottom and then left to right (unlike how
English speakers would probably read them).
Since that’s maybe confusing, it’d be easier to use two position values to index a matrix, one for the row number(s) we’re interested in and one for the column number(s) we’re interested in. We can separate these values inside our brackets using a comma, just like we do with inputs inside a function call.
For example, here’s how we’d get back the value from the 2nd row and 3rd column instead:
R
mat1[2, 3] #Second row, third column
OUTPUT
[1] -3When indexing using two index values like this, you always provide row information first and column information second. It’s just like in the game “Battleship,” in which you guess spots on a grid by saying their row identifier first.
What if we wanted back an entire row or column? We could do something like this:
R
mat1[1:3, 2] #The whole second column
OUTPUT
[1] 1 0 -1This works, but there’s an easier way. If we use a comma to create a slot, but we leave that slot blank, R interprets that blank slot as “give back all of these.” For example, if we run this command:
R
mat1[ , 2]
OUTPUT
[1] 1 0 -1We also get back the whole second column. By leaving the slot for rows blank, we’re telling R we want back all available rows.
Indexing works mostly the same way for data frames as it does for matrices, but there are a couple notable differences. For example, consider this command:
R
df1[2]
OUTPUT
y
1 a
2 b
3 c
4 d
5 eThis command returns the entire second column of our data frame instead of giving us just the second value in it, like it would have for a matrix. This is because data frames are designed to hold data sets, and columns play a really important row in working with data sets, so R “favors” columns when indexing data frames.
Another sign of this is the existence of the $ operator.
We can use $ to index columns of a data frame by their
names instead of their positions:
R
df1$y #Whole y column
OUTPUT
[1] "a" "b" "c" "d" "e"This “shortcut” doesn’t work on matrices, even ones with named columns.
Notice how the two commands we’ve just run produce different-looking outputs—the first produces a data frame as an output, while the second produces a vector. This is a good example of how there are often multiple ways in R to produce similar (but also distinct) results.
We can index/subset objects using logical tests too.
For example, the following command would return only rows with values in
column 3 of our matrix that are greater than -4:
R
mat1[mat1[,3] > -4, ]
OUTPUT
[,1] [,2] [,3]
[1,] 4 1 -2
[2,] 3 0 -3This is another nested command, so
let’s break it down. Because R reads these from the inside out, we will
too. We’ve first asked R to determine which values in the third
column of mat1 are greater than -4:
R
mat1[,3] > -4 #The inside command above
OUTPUT
[1] TRUE TRUE FALSEWe get TRUE for the first two values and FALSE for the last value.
Then, we ask R to only keep rows in mat1 that
are TRUE and exclude all rows that are FALSE, according to
that rule (and we keep all columns by leaving the column slot
blank):
R
mat1[c(TRUE, TRUE, FALSE), ] #Basically what we did.
OUTPUT
[,1] [,2] [,3]
[1,] 4 1 -2
[2,] 3 0 -3In this way, we’ve created a subset of our matrix that passes a test
we care about—something we often want to do with our data sets!
We’ll see even fancier ways to create subsets like this when we learn
the dplyr package later. Speaking of which…
Installing and loading packages
Much earlier on, we noted there are thousands of add-on packages for R. Because there are so many, it makes sense R does not come installed with all these. That would be a lot of files!
So, if we want to use these other packages (and we do), we’ll have to download and install them first. This is, thankfully, easy ( assuming we know the name of the package we want).
In a later lesson, for example, we’ll use the dplyr
(pronounced “Dee-Plier”, or “Dee-Ply-Ar”, or “Dipply-Er”) package, which
contains an amazing set of tools for cleaning and manipulating
data sets; many R users use dplyr’s tools every
day. Let’s use dplyr as our example package here.
First, we have to download and install dplyr; the
following command will do that:
R
install.packages("dplyr")
In just a few moments, you should get confirmation that
dplyr has installed (assuming you have an internet
connection!).
However, by default, R does not assume you want to actually use all the packages you have installed. Thinking back to our “room” analogy, if we had hundreds of packages on, each one full of tools and other stuff, dumping all that stuff into our “room” would make it very cluttered!
So, every time we start R, we have to manually turn on
any packages we want to use. To do this, we use the
library() function:
R
library(dplyr)
This will turn on dplyr and make all its tools and stuff
accessible.
Note we needed to quote "dplyr" in
install.packages(), but we didn’t need to in
library(). There’s not really a good reason for this—to
some degree, you have to memorize when quotes are needed (or check help
pages).
Later, if we we want to turn a package off, we can use the
detach() function:
R
detach(dplyr)
We can also check to see if packages are already on/off, install or update packages, or turn packages on/off on the Packages pane, typically found in the lower-right (though it could be elsewhere):
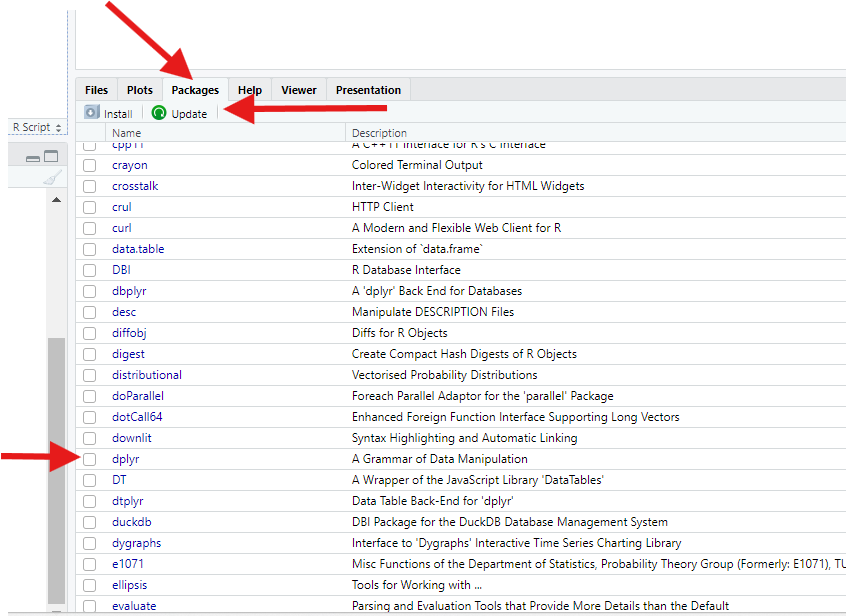
Here, you can use the “Install” and “Update” buttons at the top to install or update packages. In the table, meanwhile, you’ll find an alphabetized list of every package you have installed. If the checkbox next to a package’s name is checked, that package is on. Checking the checkbox will turn the package on; unchecking it will turn it off.
Many beginners find the Packages pane to be an easier way to deal with packages than using function calls.
Callout
Note that while you have to turn packages on every time you open R,
you only have to install a package once! For this
reason, don’t include install.package()calls in
your scripts; they are almost always unnecessary, and sometimes,
they take a long time to run!
Challenge
To practice managing packages, download and install the other
packages we’ll need for these lessons: gapminder,
ggplot2, and tidyr. Then, turn them on.
First, you’d use install.packages() to download and
install each package. We can actually put all the packages into a single
call if we want, so long as we separate them with commas. We also have
to quote each package name:
R
install.packages("gapminder", "ggplot2", "tidyr")
Then, we use library() to turn each package on. Unlike
with installation, we don’t have to quote the package
names, but we also can’t stuff all the packages into a single
call either, so turning on multiple packages is
tedious:
R
library(gapminder)
library(ggplot2)
library(tidyr)
We could just as easily do all this with the Packages pane instead, but that’d be harder to show here.
Managing your working directory
In the next section (the last in this lesson), we’ll talk about loading files into R and saving files from R. Those are things you’ll probably do often if you use R regularly!
Before that, though, we need to explain a quirky R concept: your working directory.
When you start R, R assumes that, for that session, there is a “home base” on your computer it should interact with. This “home base” is called your working directory (a “directory” is another name for a “folder”).
To figure out what your working directory is, use
the getwd() function:
R
getwd()
We can also figure out our working directory by clicking the “right arrow” at the top of the Console:
This opens our working directory in the Files pane, typically found in the bottom-right (though it could be elsewhere).
If we try to load a file into R, unless we specify otherwise, R assumes it’s in our working directory. If we save a file from R, unless we specify otherwise, R assumes it should save it into our working directory. So, it matters which folder this is!
If we want to change our working directory,
we can specify a new directory by providing a file
path to the setwd() function:
R
setwd("some/path/to/a/different_folder")
However, for beginners, file paths can be tricky, so thankfully there’s an easier way. Find “Session” at the top of your screen. There, select “Set Working Directory.” Then, click “Choose Directory…”. This’ll bring up a “file picker” on your computer, allowing you to navigate to the folder you want to choose. Much easier!
Loading and saving files
How exactly you load or save files in R depends on what exactly you are trying to load or save, understandably!
However, in general, you will use a read
function of some kind to load files. For example,
read.csv() will read data a .csv (“comma-separated values”)
file, readRDS() will read an .rds (“R data structure”)
format, and so on. Other packages add additional options; for example,
the readxl package adds the read_excel()
function for loading Microsoft Excel files.
To demonstrate how to load files into R, we need a file to load. So, let’s first make an object we can save to demonstrate how saving works. Run:
R
#Thoughtfully placed line breaks can help us see the separations between inputs in our function calls!
sampleData = data.frame(x = c(1, 2, 3),
y = c("A", "B", "C"))
This command creates a data frame with two columns
(named x and y), each with three values, so
the result has three rows. [Sidenote: We have yet another,
distinct use of = here! Here, we’re using it to give
names to the columns we’re creating. This is its job
insidecertain functions, like data.frame.]
Now, we can save this data frame as a simple .csv file using
write.csv(), which has two required inputs:
The R object we want to save, and
The name we want to give the file, which should end in “.csv”. This input must be quoted.
So, run:
R
write.csv(x = sampleData,
file = "sample.csv")
So long as that command worked, you should see your new file in your Files pane (you may need to “Refresh” the pane first using the circular arrow button in the pane’s top-right corner).
Now that we have that file, we can read it into R using
read.csv(), which takes just one required input: the name
(or path) of the file we’re loading. However, to actually make the data
set we’re loading permanent, we need to combine it with an assignment
command to give the new object a name as well:
R
sample_data = read.csv("sample.csv")
In other words, we almost always pair a read function
with an assignment command to save what we’re reading
as a named object so R won’t forget it as soon as it’s
done reading it.
RStudio offers a second way to load data that some may find easier, though it’s harder to explain here. In your Environment pane, find the “Import Dataset” button, then select the appropriate option for the format of data you want to import.
A large window will then open:
This window allows you to select the file you want to load using a file picker (towards the top). A preview of the data you’ve loaded is then provided in the center.
At the bottom-left, you’ll see options to adjust which rows to import and whether the top row should be treated as column names. You can also name your new data set object here. If you’re curious, the code needed to achieve the same outcome is displayed in the bottom-right. When you’re satisfied, hit the “Import” button.
Creating an R Project folder
We’ve seen that, when working in R, managing your environment is important, managing your working directory is important, and loading and saving files is important. All these are made easier by having an R Project folder.
When you make one, R adds a .rproj file to a folder on your computer. When you then launch R by opening this .rproj file, or when you use the “File” menu to open this file or project, R will use the contents of this .rproj file to restore your environment, package statuses, and open files to whatever they were the last time you worked on your project.
This means that, for large or complicated projects, you can “save your progress” between R sessions! Furthermore, R will assume your working directory is your project folder, which means saving and loading project files is easier (assuming you store them in your project folder, of course)!
To make an R Project folder, go to “File,” then select “New Project.” A menu will pop up; there, select “New Directory,” then select “New Project.”
On the next screen, use the file picker to select a location for your new project folder on your computer, then give it a name. Also, check the box that says “Open in New Session.” When you’re ready, press “Create Project.” This will open a new session of RStudio centered around your new Project.
Key Points
- R is an incredibly powerful tool; knowing how to use it is an incredibly valuable skill. However, to learn it takes the same diligence as learning a human language does.
- R is a very capable calculator; you can use it to do math.
- R, like human languages, has punctuation marks (operators) that have specific meanings and usage rules.
- R “sentences” are called commands. They include inputs as well as instructions for operations we want R to perform for us.
- Script files are text files that allow us to write and store code and annotations and then “teleport” this code to the Console when we’re ready.
- “Nouns” in R are called objects. These are impermanent until we use assignment commands to name them, in which case they persist until we overwrite them or close R.
- Our environment is everything we have named since starting our R session.
- There are rules about what we can and can’t (and should and shouldn’t) name objects in R.
- R is case-sensitive, so capital and lowercase letters are distinct.
- It’s good to have a naming convention to name objects.
- Objects in R take many different shapes, and the values they store can be of many different types (the “adjectives” of the R language).
- In R, “verbs” are called functions. Functions take inputs, perform operations, and produce outputs. Some functions do math; others might create new objects.
- Functions have slots for specific inputs. These slots are called parameters, and they have names. The inputs we provide to these slots are called arguments. Arguments should be given in a specific order, and they should be of specific types.
- Some function inputs are optional; others are required. Optional inputs are like R’s “adverbs” in that they often control how R performs a specific operation.
- If we want help with a function, we can use the
?operator to open its help page. - The
=symbol has many different uses in R, which can be confusing. As such, consider using<-for assignment. - Logical tests are like “questions” in R. There are many different logical operators to ask a variety of questions.
- Use the square bracket operators
[ ]to peek inside objects in indexing commands. Indexing commands can also be used to update or subset objects, and their format differs for 1D vs. 2D object types. - Installing packages is necessary to have access to them, but even then, packages must be turned on to use their features.
- Your working directory is the folder R assumes it should interact with on your computer when loading/saving files.
- R Project folders are handy for keeping organized when working on a large, important, or complex project.
- Loading files in R typically requires a
readfunction; saving files typically requires awritefunction.
Content from Exploring the Tidyverse, a modern R "dialect"
Last updated on 2025-04-15 | Edit this page
Estimated time: 180 minutes
Overview
Questions
- What are the most common types of operations someone might perform on a data frame in R?
- How can you perform these operations clearly and efficiently?
Objectives
- Subset a data set to a smaller, targeted set of rows and/or columns.
- Sort or rename columns.
- Make new columns using old columns as inputs.
- Generate summaries of a data set.
- Use pipes to string multiple operations on the same data set together into a “paragraph.”
Preparation and setup
Note: These lessons uses the gapminder data set. This data set can be accessed using the following commands:
R
install.packages("gapminder") #ONLY RUN THIS COMMAND IF YOU HAVE NOT ALREADY INSTALLED THIS PACKAGE.
OUTPUT
The following package(s) will be installed:
- gapminder [1.0.0]
These packages will be installed into "~/work/r-novice-gapminder/r-novice-gapminder/renv/profiles/lesson-requirements/renv/library/linux-ubuntu-jammy/R-4.4/x86_64-pc-linux-gnu".
# Installing packages --------------------------------------------------------
- Installing gapminder ... OK [linked from cache]
Successfully installed 1 package in 5.1 milliseconds.R
library(gapminder) #TURN THE PACKAGE ON
gap = as.data.frame(gapminder) #CREATE A VERSION OF THE DATA SET NAMED gap FOR CONVENIENCE
These lessons revolve around the packages in the so-called
“tidyverse”—a suite array of R packages containing extremely
useful tools that are all designed to look similar and work well
together. Many of these tools allow you to do operations more
efficiently, clearly, or quickly than you can in “base R.” As such, most
things we’ll do in these lessons can be done in “base R” too, but it
won’t (typically) be as efficient, clear, or fast! As such, the
tidyverse packages can be viewed as a modern “dialect” of R
that many (though not all!) R users use in place of (or in concert with)
base R in their day-to-day workflows.
dplyr, ggplot2, and tidyr, the
specific packages we’ll use in these lessons, are like many add-on
packages for R in that they do not come pre-installed
with R. We can install them using this command:
R
install.packages(c("dplyr", "ggplot2", "tidyr")) #ONLY RUN THIS COMMAND IF YOU HAVEN'T ALREADY INSTALLED THESE PACKAGES.
You only need to install a package once (just like you only need to
install a program once), so there’s no need to run the above command
more than once. [However, packages are updated occasionally. When
updates are available, you can re-install new versions using the same
install.packages() function.]
When you launch R or RStudio, none of the add-on packages you have
installed with be “turned on” by default. either So, to turn on
dplyr so that we can access its features, we use a
library() call:
R
library(dplyr) #RUN EACH TIME YOU START UP R AND WANT TO USE THIS PACKAGE'S FEATURES.
library(ggplot2)
library(tidyr)
The above command must be run every time you start up R and want to access these packages’ features.
Data Frame Manipulation with dplyr
R is designed for working with data and data sets. Because data
frames (and tibbles, their tidyverse equivalents) are the
primary object types for holding data sets in R, R users work with data
frames (and tibbles) A LOT…like, a lot a lot.
When working with data sets stores as data frames (or tibbles), we very often find ourselves needing to perform certain actions, such as cutting certain rows or columns out of these objects, renaming columns, or transforming columns into new ones.
We can do ALL of those things in “base R” if we wanted to. In fact,
our
“Welcome to R!” lessons demonstrated how to do some of these actions
in base R. However, dplyr makes doing all these things
easier, more concise, AND more intuitive. It does this by adding new
verbs (functions) to the R language that all use a consistent syntax and
structure (and have intuitive names), allowing us to write code in
connected “paragraphs” that do more than commands usually can while
also, somehow, being easier to read.
In this lesson, we’ll go through the most common dplyr
verbs, showing off their uses.
SELECT and RENAME
What if we wanted to create a subset of our current data set (a
version lacking some rows and/or columns)? When it comes to subsetting
by columns, the dplyr verb corresponding to this desire is
select().
Callout
Important: I said above that one of the strengths of
dplyr is that all its verbs share a similar structure.
Every major dplyr verb, including select(),
takes as its first input the data frame (or tibble) you’re trying to
manipulate.
After that first input, every subsequent input you provide becomes another “thing” you want the function to do to that data frame.
What I mean by that last part will become clearer via an example.
Suppose I want a new, smaller version of the gapminder data
set that is only the country and year
columns from the original. I could use select() to achieve
that desire like this:
R
gap_shrunk = select(gap, #1ST INPUT IS ALWAYS THE DATA FRAME TO BE MANIPULATED
country, year) #EACH SUBSEQUENT INPUT IS "ANOTHER THING TO DO" TO THAT DATA FRAME. HERE, IT'S THE COLUMNS WE WANT TO KEEP IN OUR SUBSET.
head(gap_shrunk)
OUTPUT
country year
1 Afghanistan 1952
2 Afghanistan 1957
3 Afghanistan 1962
4 Afghanistan 1967
5 Afghanistan 1972
6 Afghanistan 1977In the example above, I provided my data frame as the first input to
select() and then all the columns I wanted to
select as subsequent inputs. As a result, I ended up with a
shrunken version of the original data set, one containing only those two
columns.
Callout
Notice that, in the tidyverse packages, column names are
often unquoted when used as inputs.
In
our subsetting and indexing lesson, we learned some “tricks” for
subsetting objects in R. Many of those tricks with select()
too. For example, you can select a sequence of consecutive columns by
using the : operator and the names of the first and last
columns in that sequence:
R
gap_sequence = select(gap,
pop:lifeExp) #SELECT ALL COLUMNS FROM pop TO lifeExp
head(gap_sequence)
OUTPUT
pop lifeExp
1 8425333 28.801
2 9240934 30.332
3 10267083 31.997
4 11537966 34.020
5 13079460 36.088
6 14880372 38.438We can also use the - operator to specify columns we
want to reject instead of keep. For example, to retain every
column except year, we could do this:
R
gap_noyear = select(gap,
-year) #EXCLUDE YEAR FROM THE SUBSET
head(gap_noyear)
OUTPUT
country continent lifeExp pop gdpPercap
1 Afghanistan Asia 28.801 8425333 779.4453
2 Afghanistan Asia 30.332 9240934 820.8530
3 Afghanistan Asia 31.997 10267083 853.1007
4 Afghanistan Asia 34.020 11537966 836.1971
5 Afghanistan Asia 36.088 13079460 739.9811
6 Afghanistan Asia 38.438 14880372 786.1134We can also use select() to rearrange columns
by specifying the column names in the new order we want them in:
R
gap_reordered = select(gap,
year, country) #THE ORDER HERE SPECIFIES THE ORDER IN THE SUBSET
head(gap_reordered)
OUTPUT
year country
1 1952 Afghanistan
2 1957 Afghanistan
3 1962 Afghanistan
4 1967 Afghanistan
5 1972 Afghanistan
6 1977 AfghanistanRenaming
What if wanted to rename some of our columns? The dplyr
verb corresponding to this desire is, fittingly,
rename().
As with select() (and all dplyr
verbs!), rename()’s first input is the data frame we’re
manipulating. Each subsequent input is an “instructions list” for how to
do that renaming, with the new name to give to a column to the left of
an = operator and the old name of that column to the right
of it (what I like to call new = old format).
For example, to rename the pop column to “population,”
which I would personally find to be more informative, we would
do the following:
R
gap_renamed = rename(gap,
population = pop) #NEW = OLD FORMAT TO RENAME COLUMNS
head(gap_renamed)
OUTPUT
country continent year lifeExp population gdpPercap
1 Afghanistan Asia 1952 28.801 8425333 779.4453
2 Afghanistan Asia 1957 30.332 9240934 820.8530
3 Afghanistan Asia 1962 31.997 10267083 853.1007
4 Afghanistan Asia 1967 34.020 11537966 836.1971
5 Afghanistan Asia 1972 36.088 13079460 739.9811
6 Afghanistan Asia 1977 38.438 14880372 786.1134It’s as simple as that! If we wanted to rename multiple columns at
once, we could add more inputs to the same rename()
call.
Magical pipes
Challenge
What if I wanted to first eliminate some columns and then rename some of the remaining columns? How would you accomplish that goal, based on what I’ve taught you so far?
Your first impulse might be to do this in two commands, saving intermediate objects at each step, like so:
R
gap_selected = select(gap,
country:pop) #FIRST, CREATE OUR SUBSET, AND SAVE AN INTERMEDIATE OBJECT CALLED gap_selected.
gap_remonikered = rename(gap_selected,
population = pop) #USE THAT OBJECT IN THE RENAMING COMMAND.
head(gap_remonikered)
OUTPUT
country continent year lifeExp population
1 Afghanistan Asia 1952 28.801 8425333
2 Afghanistan Asia 1957 30.332 9240934
3 Afghanistan Asia 1962 31.997 10267083
4 Afghanistan Asia 1967 34.020 11537966
5 Afghanistan Asia 1972 36.088 13079460
6 Afghanistan Asia 1977 38.438 14880372There’s nothing wrong with this approach, but it’s…tedious. Plus, if you don’t pick really good names for each intermediate object, it can get confusing for you and others to read.
I hope you’re thinking “I bet there’s a better way.” And there is! We can combine these two discrete “sentences” into one, easy-to-read “paragraph.” The only catch is we have to use a strange operator called a pipe to do it.
dplyr pipes look like this: %>%. On
Windows, the hotkey to render a pipe is Control + shift + m! On Mac,
it’s similar: Command + shift + m.
Callout
Pipes may look a little funny, but they do something really cool. They take the “thing” produced on their left (once all operations over there are complete) and “pump” that thing into the operations on their right automatically, specifically into the first available input slot.
This is easier to explain with an example, so let’s see how to use pipes to perform the two operations we did above in a single command:
R
gap.final = gap %>% #START WITH OUR RAW DATA SET, THEN PIPE IT INTO...
select(country:pop) %>% #OUR SELECT CALL, THEN PIPE THE RESULT INTO...
rename(population = pop) #OUR RENAME CALL. PIPES ALWAYS PLACE THEIR "BURDENS" IN THE FIRST AVAILABLE INPUT SLOT, WHICH IS WHERE dplyr VERBS EXPECT THE DATA FRAME TO GO ANYWAY!
head(gap.final)
OUTPUT
country continent year lifeExp population
1 Afghanistan Asia 1952 28.801 8425333
2 Afghanistan Asia 1957 30.332 9240934
3 Afghanistan Asia 1962 31.997 10267083
4 Afghanistan Asia 1967 34.020 11537966
5 Afghanistan Asia 1972 36.088 13079460
6 Afghanistan Asia 1977 38.438 14880372The command above says: “Take the raw gapminder data set
and pump it into select()’s first input slot (where it
belongs anyway). Then, do select()’s operations (which
yield a new, subsetted data set) and pump that into
rename()’s first input slot. Then, when that function is
done, save the result into an object called gap.final.”
Hopefully, you can see how “dplyr paragraphs” like this
one could be easier to read and follow along with but more
code-efficient too! The existence of pipes also explains why every
dplyr verb’s first input slot is the data frame to be
manipulated—it makes every verb ready to receive “upstream” inputs via a
pipe!
Pipes are so useful to writing clean, efficient
tidyverse code that few tidyverse users eschew
them. So, we’ll be using them for the rest of this lesson and the ones
beyond, so you’ll get plenty of practice with them!
FILTER, ARRANGE, and MUTATE
What if we only wanted to look at data from a specific continent or a
specific time frame (i.e., we wanted to subset by rows
instead)? The dplyr verb corresponding to this desire is
filter() (see, I said dplyr verbs have
intuitive names!).
Each input given to filter() past the first (which is
ALWAYS the data frame to be manipulated, as we’ve established!) is a
logical test, a construction we’ve seen before.
Each logical testhere willconsist of the name of the
column we’ll check the values of, a logical operator
(like == for “is equal to” or <= for “is
less than or equal to”), and a “threshold” to check the values in that
column against.
If all the logical tests pass for a particular row, we keep that row. Otherwise, we remove that row from the new, subsetted data frame we create.
For example, here’s how we’d filter our data set to just rows where
the value in the continent column is exactly
"Europe":
R
gap_europe = gap %>%
filter(continent == "Europe") #THE COLUMN TO CHECK VALUES IN, AN OPERATOR, THEN THE THRESHOLD VALUE TO CHECK THEM AGAINST.
head(gap_europe)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Albania Europe 1952 55.23 1282697 1601.056
2 Albania Europe 1957 59.28 1476505 1942.284
3 Albania Europe 1962 64.82 1728137 2312.889
4 Albania Europe 1967 66.22 1984060 2760.197
5 Albania Europe 1972 67.69 2263554 3313.422
6 Albania Europe 1977 68.93 2509048 3533.004As another example, here’s how we’d filter our data set to just rows
with data from before the year 1975:
R
gap_pre1975 = gap %>%
filter(year < 1975)
head(gap_pre1975)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Afghanistan Asia 1952 28.801 8425333 779.4453
2 Afghanistan Asia 1957 30.332 9240934 820.8530
3 Afghanistan Asia 1962 31.997 10267083 853.1007
4 Afghanistan Asia 1967 34.020 11537966 836.1971
5 Afghanistan Asia 1972 36.088 13079460 739.9811
6 Albania Europe 1952 55.230 1282697 1601.0561Challenge
What if we wanted data only from between the years 1970 and
1979? How would you achieve this goal using filter()? Hint:
There are at least three valid ways you should be able to think
of to do this!
The first solution is to use & (R’s “AND” operator)
to specify two rules a value in the year column must
satisfy to pass:
R
and_option = gap %>%
filter(year > 1969 &
year < 1980) #YOU COULD USE LESS THAN OR EQUAL TO OPERATORS HERE ALSO, BUT DIFFERENT YEAR VALUES WOULD BE NEEDED.
However, I said earlier that every input to filter()
past the first is another logical test a row
must satisfy to pass. So, just specifying two logical
testshere, with a comma in between, has the same effect:
R
comma_option = gap %>%
filter(year > 1969,
year < 1980)
Of course, if you prefer, you can use multiple filter()
calls back to back, each containing just one rule:
R
stacked_option = gap %>%
filter(year > 1969) %>%
filter(year < 1980)
None of these approaches is “right” or “wrong,” so you can decide which ones you prefer!
Challenge
Important: When chaining dplyr verbs
together in “paragraphs” via pipes, order matters! Why
does the following code trigger an error when
executed?
R
this_will_fail = gap %>%
select(pop:lifeExp) %>%
filter(year < 1975)
Recall that the year column is not one of the
columns between the pop and lifeExp columns.
So, the year column gets cuts by the select()
call here before we get to the filter() call that
tries to use it as an input, so the filter() call fails to
find that column.
Considering that dplyr “paragraphs” can get long and
complicated, remember to be thoughtful about the order you specify
actions in!
Sorting
What if we wanted to sort our data set by the values in one
(or more) columns? The dplyr verb corresponding to this
desire is arrange().
Every input past the first given to arrange() is a
column we want to sort by, with earlier columns taking “precedence” over
later ones.
For example, here’s how we’d sort our data set by the
lifeExp column (in ascending order):
R
gap_sorted = gap %>%
arrange(lifeExp)
head(gap_sorted)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Rwanda Africa 1992 23.599 7290203 737.0686
2 Afghanistan Asia 1952 28.801 8425333 779.4453
3 Gambia Africa 1952 30.000 284320 485.2307
4 Angola Africa 1952 30.015 4232095 3520.6103
5 Sierra Leone Africa 1952 30.331 2143249 879.7877
6 Afghanistan Asia 1957 30.332 9240934 820.8530Ascending order is the default for arrange(). If we want
to reverse it, we use the desc() helper function:
R
gap_sorted_down = gap %>%
arrange(desc(lifeExp)) #DESCENDING ORDER INSTEAD.
head(gap_sorted_down)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Japan Asia 2007 82.603 127467972 31656.07
2 Hong Kong, China Asia 2007 82.208 6980412 39724.98
3 Japan Asia 2002 82.000 127065841 28604.59
4 Iceland Europe 2007 81.757 301931 36180.79
5 Switzerland Europe 2007 81.701 7554661 37506.42
6 Hong Kong, China Asia 2002 81.495 6762476 30209.02Challenge
I mentioned above that you can provide multiple inputs to
arrange(), but it’s a little hard to explain what
this does, so let’s try it and see what happens:
R
gap_2xsorted = gap %>%
arrange(year, continent)
head(gap_2xsorted)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Algeria Africa 1952 43.077 9279525 2449.0082
2 Angola Africa 1952 30.015 4232095 3520.6103
3 Benin Africa 1952 38.223 1738315 1062.7522
4 Botswana Africa 1952 47.622 442308 851.2411
5 Burkina Faso Africa 1952 31.975 4469979 543.2552
6 Burundi Africa 1952 39.031 2445618 339.2965What did this command do? Why? What would change if you reversed the
order of continent and year in the call?
This command first sorted the data set by the unique values
in the year column. It then “broke any ties,” in which 2+
rows have the same year value, by then
sorting by the continent column’s values within each of
those tied groups.
So, we get records for Africa sooner than we get records
for Asia for the same year, but records from
Africa and Asia alternate as we go through all
the years. If we reversed the order of our two inputs, we’d instead get
all records for Africa, in chronological order by
year, before getting any records for
Asia.
This mirrors the behavior of “multi-column sorting” as it exists in programs like Microsoft Excel.
Generating new columns
What if we wanted to make a new column using an old column’s values
as inputs? This is the kind of thing many of us are used to doing in
Microsoft Excel, where it isn’t always easy or reproducible. Thankfully,
we have the dplyr verb mutate() to match with
this desire.
Every input to mutate() past the first is an
“instructions list” for how to make a new column using one or more old
columns as inputs, and these follow new = old format
again.
For example, here’s how we would create a new column called
pop1K that is made by dividing the pop
column’s values by 1000:
R
gap_newcol = gap %>%
mutate(pop1K = round(pop / 1000)) #NEW = OLD FORMAT. WHAT WILL THE NEW COLUMN BE CALLED, AND HOW SHOULD WE OPERATE ON THE OLD COLUMN TO MAKE IT?
head(gap_newcol)
OUTPUT
country continent year lifeExp pop gdpPercap pop1K
1 Afghanistan Asia 1952 28.801 8425333 779.4453 8425
2 Afghanistan Asia 1957 30.332 9240934 820.8530 9241
3 Afghanistan Asia 1962 31.997 10267083 853.1007 10267
4 Afghanistan Asia 1967 34.020 11537966 836.1971 11538
5 Afghanistan Asia 1972 36.088 13079460 739.9811 13079
6 Afghanistan Asia 1977 38.438 14880372 786.1134 14880You’ll note that the old pop column still exists after
this command. If you want to get rid of it, now that you’ve used it, you
can specify the input .keep = "unused" to
mutate() and it will eliminate any columns used to create
new ones. Try it!
GROUP_BY and SUMMARIZE
One the most powerful actions we might want to take on a data set is to generate a summary. “What’s the mean of this column?” or “What’s the median value for all the different groups in that column?”, for example.
Suppose we wanted to calculate the mean life expectancy across all
years for each country. We could use filter() to
go country by country, save each subset as an intermediate
object, and then take a mean of each subset’s
lifeExp column. It’d work, but what a pain it’d
be!
Thankfully, we don’t have to; instead, we can use the
dplyr verbs group_by() and
summarize()! Unlike other dplyr verbs we’ve
met so far, these are a duo—they’re generally used together
and, importantly, we always use group_by() first
when we do use them as a pair.
So, let’s start by understanding what group_by() does.
Each input given to group_by() past the first creates
groupings in the data. Specifically, you provide a column name, and R
will find all the different values in that column (such as all the
different unique country names) and subtly “bundle up” all the rows that
possess each different value.
…This is easier to show you than to explain, so let’s try it:
R
gap_grouped = gap %>%
group_by(country) #FIND EACH UNIQUE COUNTRY AND BUNDLE ROWS FROM THE SAME COUNTRY TOGETHER.
head(gap_grouped)
OUTPUT
# A tibble: 6 × 6
# Groups: country [1]
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.When we look at the new data set, it will look as though
nothing has changed. And, in a lot of ways, nothing has! However, if you
examine gap_grouped in your RStudio’s ‘Environment’ Pane,
you’ll notice that gap_grouped is considered a “grouped
data frame” instead of a plain-old one.
We can see what that means by using the str()
(“structure”) function to peek “under the hood” at
gap_grouped:
R
str(gap_grouped)
OUTPUT
gropd_df [1,704 × 6] (S3: grouped_df/tbl_df/tbl/data.frame)
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ year : int [1:1704] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ lifeExp : num [1:1704] 28.8 30.3 32 34 36.1 ...
$ pop : int [1:1704] 8425333 9240934 10267083 11537966 13079460 14880372 12881816 13867957 16317921 22227415 ...
$ gdpPercap: num [1:1704] 779 821 853 836 740 ...
- attr(*, "groups")= tibble [142 × 2] (S3: tbl_df/tbl/data.frame)
..$ country: Factor w/ 142 levels "Afghanistan",..: 1 2 3 4 5 6 7 8 9 10 ...
..$ .rows : list<int> [1:142]
.. ..$ : int [1:12] 1 2 3 4 5 6 7 8 9 10 ...
.. ..$ : int [1:12] 13 14 15 16 17 18 19 20 21 22 ...
.. ..$ : int [1:12] 25 26 27 28 29 30 31 32 33 34 ...
.. ..$ : int [1:12] 37 38 39 40 41 42 43 44 45 46 ...
.. ..$ : int [1:12] 49 50 51 52 53 54 55 56 57 58 ...
.. ..$ : int [1:12] 61 62 63 64 65 66 67 68 69 70 ...
.. ..$ : int [1:12] 73 74 75 76 77 78 79 80 81 82 ...
.. ..$ : int [1:12] 85 86 87 88 89 90 91 92 93 94 ...
.. ..$ : int [1:12] 97 98 99 100 101 102 103 104 105 106 ...
.. ..$ : int [1:12] 109 110 111 112 113 114 115 116 117 118 ...
.. ..$ : int [1:12] 121 122 123 124 125 126 127 128 129 130 ...
.. ..$ : int [1:12] 133 134 135 136 137 138 139 140 141 142 ...
.. ..$ : int [1:12] 145 146 147 148 149 150 151 152 153 154 ...
.. ..$ : int [1:12] 157 158 159 160 161 162 163 164 165 166 ...
.. ..$ : int [1:12] 169 170 171 172 173 174 175 176 177 178 ...
.. ..$ : int [1:12] 181 182 183 184 185 186 187 188 189 190 ...
.. ..$ : int [1:12] 193 194 195 196 197 198 199 200 201 202 ...
.. ..$ : int [1:12] 205 206 207 208 209 210 211 212 213 214 ...
.. ..$ : int [1:12] 217 218 219 220 221 222 223 224 225 226 ...
.. ..$ : int [1:12] 229 230 231 232 233 234 235 236 237 238 ...
.. ..$ : int [1:12] 241 242 243 244 245 246 247 248 249 250 ...
.. ..$ : int [1:12] 253 254 255 256 257 258 259 260 261 262 ...
.. ..$ : int [1:12] 265 266 267 268 269 270 271 272 273 274 ...
.. ..$ : int [1:12] 277 278 279 280 281 282 283 284 285 286 ...
.. ..$ : int [1:12] 289 290 291 292 293 294 295 296 297 298 ...
.. ..$ : int [1:12] 301 302 303 304 305 306 307 308 309 310 ...
.. ..$ : int [1:12] 313 314 315 316 317 318 319 320 321 322 ...
.. ..$ : int [1:12] 325 326 327 328 329 330 331 332 333 334 ...
.. ..$ : int [1:12] 337 338 339 340 341 342 343 344 345 346 ...
.. ..$ : int [1:12] 349 350 351 352 353 354 355 356 357 358 ...
.. ..$ : int [1:12] 361 362 363 364 365 366 367 368 369 370 ...
.. ..$ : int [1:12] 373 374 375 376 377 378 379 380 381 382 ...
.. ..$ : int [1:12] 385 386 387 388 389 390 391 392 393 394 ...
.. ..$ : int [1:12] 397 398 399 400 401 402 403 404 405 406 ...
.. ..$ : int [1:12] 409 410 411 412 413 414 415 416 417 418 ...
.. ..$ : int [1:12] 421 422 423 424 425 426 427 428 429 430 ...
.. ..$ : int [1:12] 433 434 435 436 437 438 439 440 441 442 ...
.. ..$ : int [1:12] 445 446 447 448 449 450 451 452 453 454 ...
.. ..$ : int [1:12] 457 458 459 460 461 462 463 464 465 466 ...
.. ..$ : int [1:12] 469 470 471 472 473 474 475 476 477 478 ...
.. ..$ : int [1:12] 481 482 483 484 485 486 487 488 489 490 ...
.. ..$ : int [1:12] 493 494 495 496 497 498 499 500 501 502 ...
.. ..$ : int [1:12] 505 506 507 508 509 510 511 512 513 514 ...
.. ..$ : int [1:12] 517 518 519 520 521 522 523 524 525 526 ...
.. ..$ : int [1:12] 529 530 531 532 533 534 535 536 537 538 ...
.. ..$ : int [1:12] 541 542 543 544 545 546 547 548 549 550 ...
.. ..$ : int [1:12] 553 554 555 556 557 558 559 560 561 562 ...
.. ..$ : int [1:12] 565 566 567 568 569 570 571 572 573 574 ...
.. ..$ : int [1:12] 577 578 579 580 581 582 583 584 585 586 ...
.. ..$ : int [1:12] 589 590 591 592 593 594 595 596 597 598 ...
.. ..$ : int [1:12] 601 602 603 604 605 606 607 608 609 610 ...
.. ..$ : int [1:12] 613 614 615 616 617 618 619 620 621 622 ...
.. ..$ : int [1:12] 625 626 627 628 629 630 631 632 633 634 ...
.. ..$ : int [1:12] 637 638 639 640 641 642 643 644 645 646 ...
.. ..$ : int [1:12] 649 650 651 652 653 654 655 656 657 658 ...
.. ..$ : int [1:12] 661 662 663 664 665 666 667 668 669 670 ...
.. ..$ : int [1:12] 673 674 675 676 677 678 679 680 681 682 ...
.. ..$ : int [1:12] 685 686 687 688 689 690 691 692 693 694 ...
.. ..$ : int [1:12] 697 698 699 700 701 702 703 704 705 706 ...
.. ..$ : int [1:12] 709 710 711 712 713 714 715 716 717 718 ...
.. ..$ : int [1:12] 721 722 723 724 725 726 727 728 729 730 ...
.. ..$ : int [1:12] 733 734 735 736 737 738 739 740 741 742 ...
.. ..$ : int [1:12] 745 746 747 748 749 750 751 752 753 754 ...
.. ..$ : int [1:12] 757 758 759 760 761 762 763 764 765 766 ...
.. ..$ : int [1:12] 769 770 771 772 773 774 775 776 777 778 ...
.. ..$ : int [1:12] 781 782 783 784 785 786 787 788 789 790 ...
.. ..$ : int [1:12] 793 794 795 796 797 798 799 800 801 802 ...
.. ..$ : int [1:12] 805 806 807 808 809 810 811 812 813 814 ...
.. ..$ : int [1:12] 817 818 819 820 821 822 823 824 825 826 ...
.. ..$ : int [1:12] 829 830 831 832 833 834 835 836 837 838 ...
.. ..$ : int [1:12] 841 842 843 844 845 846 847 848 849 850 ...
.. ..$ : int [1:12] 853 854 855 856 857 858 859 860 861 862 ...
.. ..$ : int [1:12] 865 866 867 868 869 870 871 872 873 874 ...
.. ..$ : int [1:12] 877 878 879 880 881 882 883 884 885 886 ...
.. ..$ : int [1:12] 889 890 891 892 893 894 895 896 897 898 ...
.. ..$ : int [1:12] 901 902 903 904 905 906 907 908 909 910 ...
.. ..$ : int [1:12] 913 914 915 916 917 918 919 920 921 922 ...
.. ..$ : int [1:12] 925 926 927 928 929 930 931 932 933 934 ...
.. ..$ : int [1:12] 937 938 939 940 941 942 943 944 945 946 ...
.. ..$ : int [1:12] 949 950 951 952 953 954 955 956 957 958 ...
.. ..$ : int [1:12] 961 962 963 964 965 966 967 968 969 970 ...
.. ..$ : int [1:12] 973 974 975 976 977 978 979 980 981 982 ...
.. ..$ : int [1:12] 985 986 987 988 989 990 991 992 993 994 ...
.. ..$ : int [1:12] 997 998 999 1000 1001 1002 1003 1004 1005 1006 ...
.. ..$ : int [1:12] 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 ...
.. ..$ : int [1:12] 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 ...
.. ..$ : int [1:12] 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 ...
.. ..$ : int [1:12] 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 ...
.. ..$ : int [1:12] 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 ...
.. ..$ : int [1:12] 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 ...
.. ..$ : int [1:12] 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 ...
.. ..$ : int [1:12] 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 ...
.. ..$ : int [1:12] 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 ...
.. ..$ : int [1:12] 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 ...
.. ..$ : int [1:12] 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 ...
.. ..$ : int [1:12] 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 ...
.. ..$ : int [1:12] 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 ...
.. ..$ : int [1:12] 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 ...
.. ..$ : int [1:12] 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 ...
.. .. [list output truncated]
.. ..@ ptype: int(0)
..- attr(*, ".drop")= logi TRUEIf we look towards the bottom of this output, we’ll see that, for
every unique value in the country column, there is now a
list of all the row numbers of rows sharing that country value
(i.e., all the rows for "Afghanistan", all the
rows for "Albania", etc.).
In other words, R now knows that each row belongs to one specific group within the larger data set. So, when we then ask it to calculate a summary, it can do so for each group separately.
Let’s see how that works by next examining summarize().
Each input past the first given to summarize() is an
“instructions list” for how to generate a summary, with these
“instructions lists” once again taking new = old format
(see, I said these tools were designed to be consistent!).
For example, let’s tell summarize() to calculate a mean
life expectancy for every country and to call the new column holding
those summary values mean_lifeExp:
R
gap_summarized = gap_grouped %>% #USE THE GROUPED DATA FRAME AS THE INPUT HERE!
summarize(mean_lifeExp = mean(lifeExp)) #USE THE OLD COLUMN TO CALCULATE MEANS, THEN NAME THE RESULT mean_lifeExp. THE MEANS WILL BE CALCULATED SEPARATE FOR EACH GROUP BECAUSE WE HAVE A GROUPED DATA FRAME.
head(gap_summarized)
OUTPUT
# A tibble: 6 × 2
country mean_lifeExp
<fct> <dbl>
1 Afghanistan 37.5
2 Albania 68.4
3 Algeria 59.0
4 Angola 37.9
5 Argentina 69.1
6 Australia 74.7Challenge
Consider: How many rows does gap_summarized have? Why
does it have so many fewer rows than gap_grouped did? Where
did all the other columns go?
gap_summarized only has 142 rows, whereas
gap_grouped had 1,704. The reason for this is that we
summarized our data by group; we asked R to give us a
single value (a mean) for each group in our data set. There are
only 142 countries in the gapminder data set, so we end up
with a single row for each country.
But where did all the other columns go? Well, we didn’t ask for
summaries of those other columns too. So, if there used to be 12 values
of pop for a given country before summarization,
but there’s going to be just a single row for a given country
after summarization, and we don’t tell R how to “collapse”
those 12 values down to just one, it’s more “responsible” for R to just
drop those columns entirely rather than guess how it should do that
collapsing. That’s the logic, anyway!
If you want to generate multiple summaries, you can provide multiple
inputs to summarize(). For example, n() is a
handy function for counting up the number of data points in each group
prior to any summarization:
R
gap_summarized = gap_grouped %>%
summarize(mean_lifeExp = mean(lifeExp),
sample_sizes = n())
head(gap_summarized)
OUTPUT
# A tibble: 6 × 3
country mean_lifeExp sample_sizes
<fct> <dbl> <int>
1 Afghanistan 37.5 12
2 Albania 68.4 12
3 Algeria 59.0 12
4 Angola 37.9 12
5 Argentina 69.1 12
6 Australia 74.7 12Here, all the values in our new sample_sizes column are
12 because we have exactly 12 records per country to start
with, but if the numbers of records differed between countries, the
above operation would have shown us that.
Challenge
One more concept: You can provide multiple inputs to
group_by(), just as with any other dplyr verb.
What happens when we do? Let’s try it:
R
gap_2xgrouped = gap %>%
group_by(continent, year)
str(gap_2xgrouped)
OUTPUT
gropd_df [1,704 × 6] (S3: grouped_df/tbl_df/tbl/data.frame)
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ year : int [1:1704] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ lifeExp : num [1:1704] 28.8 30.3 32 34 36.1 ...
$ pop : int [1:1704] 8425333 9240934 10267083 11537966 13079460 14880372 12881816 13867957 16317921 22227415 ...
$ gdpPercap: num [1:1704] 779 821 853 836 740 ...
- attr(*, "groups")= tibble [60 × 3] (S3: tbl_df/tbl/data.frame)
..$ continent: Factor w/ 5 levels "Africa","Americas",..: 1 1 1 1 1 1 1 1 1 1 ...
..$ year : int [1:60] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
..$ .rows : list<int> [1:60]
.. ..$ : int [1:52] 25 37 121 157 193 205 229 253 265 313 ...
.. ..$ : int [1:52] 26 38 122 158 194 206 230 254 266 314 ...
.. ..$ : int [1:52] 27 39 123 159 195 207 231 255 267 315 ...
.. ..$ : int [1:52] 28 40 124 160 196 208 232 256 268 316 ...
.. ..$ : int [1:52] 29 41 125 161 197 209 233 257 269 317 ...
.. ..$ : int [1:52] 30 42 126 162 198 210 234 258 270 318 ...
.. ..$ : int [1:52] 31 43 127 163 199 211 235 259 271 319 ...
.. ..$ : int [1:52] 32 44 128 164 200 212 236 260 272 320 ...
.. ..$ : int [1:52] 33 45 129 165 201 213 237 261 273 321 ...
.. ..$ : int [1:52] 34 46 130 166 202 214 238 262 274 322 ...
.. ..$ : int [1:52] 35 47 131 167 203 215 239 263 275 323 ...
.. ..$ : int [1:52] 36 48 132 168 204 216 240 264 276 324 ...
.. ..$ : int [1:25] 49 133 169 241 277 301 349 385 433 445 ...
.. ..$ : int [1:25] 50 134 170 242 278 302 350 386 434 446 ...
.. ..$ : int [1:25] 51 135 171 243 279 303 351 387 435 447 ...
.. ..$ : int [1:25] 52 136 172 244 280 304 352 388 436 448 ...
.. ..$ : int [1:25] 53 137 173 245 281 305 353 389 437 449 ...
.. ..$ : int [1:25] 54 138 174 246 282 306 354 390 438 450 ...
.. ..$ : int [1:25] 55 139 175 247 283 307 355 391 439 451 ...
.. ..$ : int [1:25] 56 140 176 248 284 308 356 392 440 452 ...
.. ..$ : int [1:25] 57 141 177 249 285 309 357 393 441 453 ...
.. ..$ : int [1:25] 58 142 178 250 286 310 358 394 442 454 ...
.. ..$ : int [1:25] 59 143 179 251 287 311 359 395 443 455 ...
.. ..$ : int [1:25] 60 144 180 252 288 312 360 396 444 456 ...
.. ..$ : int [1:33] 1 85 97 217 289 661 697 709 721 733 ...
.. ..$ : int [1:33] 2 86 98 218 290 662 698 710 722 734 ...
.. ..$ : int [1:33] 3 87 99 219 291 663 699 711 723 735 ...
.. ..$ : int [1:33] 4 88 100 220 292 664 700 712 724 736 ...
.. ..$ : int [1:33] 5 89 101 221 293 665 701 713 725 737 ...
.. ..$ : int [1:33] 6 90 102 222 294 666 702 714 726 738 ...
.. ..$ : int [1:33] 7 91 103 223 295 667 703 715 727 739 ...
.. ..$ : int [1:33] 8 92 104 224 296 668 704 716 728 740 ...
.. ..$ : int [1:33] 9 93 105 225 297 669 705 717 729 741 ...
.. ..$ : int [1:33] 10 94 106 226 298 670 706 718 730 742 ...
.. ..$ : int [1:33] 11 95 107 227 299 671 707 719 731 743 ...
.. ..$ : int [1:33] 12 96 108 228 300 672 708 720 732 744 ...
.. ..$ : int [1:30] 13 73 109 145 181 373 397 409 517 529 ...
.. ..$ : int [1:30] 14 74 110 146 182 374 398 410 518 530 ...
.. ..$ : int [1:30] 15 75 111 147 183 375 399 411 519 531 ...
.. ..$ : int [1:30] 16 76 112 148 184 376 400 412 520 532 ...
.. ..$ : int [1:30] 17 77 113 149 185 377 401 413 521 533 ...
.. ..$ : int [1:30] 18 78 114 150 186 378 402 414 522 534 ...
.. ..$ : int [1:30] 19 79 115 151 187 379 403 415 523 535 ...
.. ..$ : int [1:30] 20 80 116 152 188 380 404 416 524 536 ...
.. ..$ : int [1:30] 21 81 117 153 189 381 405 417 525 537 ...
.. ..$ : int [1:30] 22 82 118 154 190 382 406 418 526 538 ...
.. ..$ : int [1:30] 23 83 119 155 191 383 407 419 527 539 ...
.. ..$ : int [1:30] 24 84 120 156 192 384 408 420 528 540 ...
.. ..$ : int [1:2] 61 1093
.. ..$ : int [1:2] 62 1094
.. ..$ : int [1:2] 63 1095
.. ..$ : int [1:2] 64 1096
.. ..$ : int [1:2] 65 1097
.. ..$ : int [1:2] 66 1098
.. ..$ : int [1:2] 67 1099
.. ..$ : int [1:2] 68 1100
.. ..$ : int [1:2] 69 1101
.. ..$ : int [1:2] 70 1102
.. ..$ : int [1:2] 71 1103
.. ..$ : int [1:2] 72 1104
.. ..@ ptype: int(0)
..- attr(*, ".drop")= logi TRUEHow did R group together rows in this case?
Next, try generating mean life expectancies and sample sizes using
gap_2xgrouped as an input. You’ll get different values than
we did before, and we’ll also get a different number of rows in the
resulting output. Why?
First, here’s the code we’d to write to generate the summaries described above:
R
gap_2xsummarized = gap_2xgrouped %>%
summarize(mean_lifeExp = mean(lifeExp),
sample_sizes = n())
head(gap_2xsummarized)
OUTPUT
# A tibble: 6 × 4
# Groups: continent [1]
continent year mean_lifeExp sample_sizes
<fct> <int> <dbl> <int>
1 Africa 1952 39.1 52
2 Africa 1957 41.3 52
3 Africa 1962 43.3 52
4 Africa 1967 45.3 52
5 Africa 1972 47.5 52
6 Africa 1977 49.6 52By specifying multiple columns to group by, what R did is find the
rows belonging to each unique combination of the values across
the two columns we specified. That is, here, it found the rows that
belong to each unique continent x year combo
and made those a group.
So, when we then summarized that grouped data frame, R calculated
summaries for each unique continent and year
combo. Because there are differing numbers of countries in each
continent, our sample sizes now differ.
Bonus: Joins
It’s common to store related data in several, smaller tables rather than together in one large table, especially if the data are of different lengths or come from different sources.
However, it may sometimes be convenient, or even necessary, to pull these related data together into one data set to analyze or graph them.
When we combine together multiple, smaller tables of data into a single larger table, that’s called a join. Joins are a straightforward operation for computers to perform, but they can be tricky for humans to conceptualize, in part because they can take so many forms:
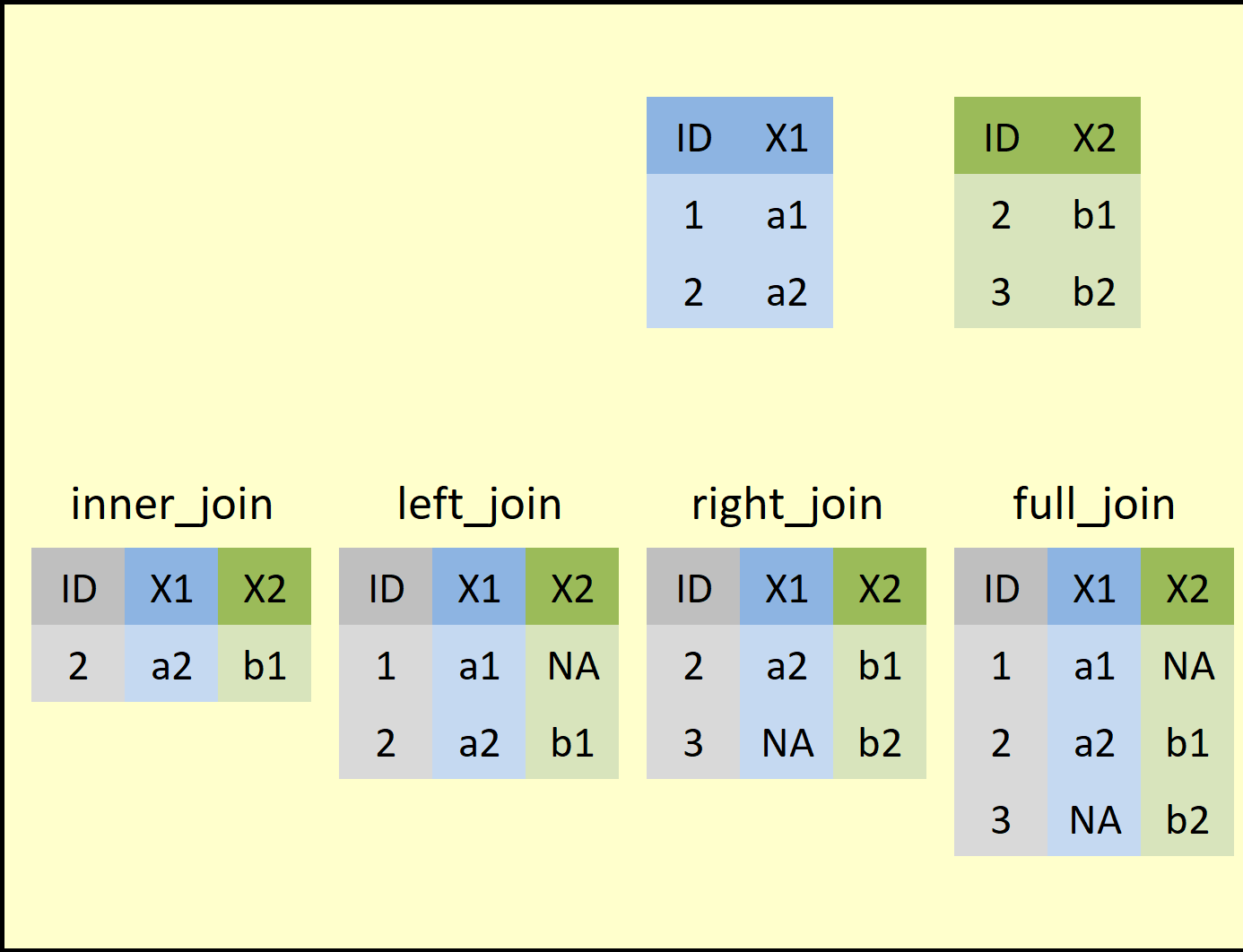
Here are the key ideas behind a join:
A join occurs between two tables: a “left” table and a “right” table. They’re called this just because we have to specify them in some order in our join command, so one will, by necessity, be to the “left” of the other.
-
The goal of a join is (usually) to make a “bigger” table by uniting related data found across the two smaller tables in some way. We’ll do that by:
Adding data from one table onto existing rows of the other table, making the receiving table wider (this is the idea behind left and right joins), or, in addition, by
Adding whole rows from one table to the other table that were “new” to the receiving table (that’s the idea behind a full join).
The exception is an inner join. An inner join will usually result in a smaller final table because we only keep, in the end, rows that had matches in both tables. Records that fail to match are eliminated.
-
But, wait, how do we know if data in one table “matches” data in another table and thus should be joined?
Well, because data found in the same row of a data set are usually related (they’re from the same country, person, group, etc.), relatedness is a “rowwise” question. We ask “which row(s) in this table are related to which row(s) in that table?”
Because computers can’t “guess” about relatedness, relatedness has to be explicit for a join to work: for rows to be considered related, they have to have matching values for one or more sets of key columns.
-
For example, in the picture above, consider the
IDcolumn that exists in both tables. If theIDcolumns were our key columns, row 1 in the left table, with itsIDvalue of1, would have no matching row in the right table (there is no row in that table with anIDvalue of1also). Thus, there is no new info in the right-hand table that could be added to the left-hand table for this row.- By contrast, row 2 in the left table, with its
IDvalue of2, does have a matching row in the right-hand table because its first row also has anIDvalue of2. Thus, we could combine these two rows in some way, either by adding new information from the right-hand table’s row to the left-hand table’s row or vice versa.
- By contrast, row 2 in the left table, with its
An analogy that might make this make relatable is to think of joins like combining jigsaw puzzle pieces. We can only connect together two puzzle pieces into something larger if they have corresponding “connectors;” matching key-column values are those connectors in a join.
Joins are a very powerful data manipulation—one many users
might otherwise have to perform in a language such as SQL. However,
dplyr possesses a full suite of joining functions,
including left_join() and right_join(),
full_join(), and inner_join(), to allow R
users to perform joins with ease.
Because a left join is the easiest form to explain and is also the
most commonly performed type of join, let’s use dplyr’s
left_join() function to add new information to every row of
the gapminder data set.
We’ll do this by first retrieving a new data set that
also possesses a column containing country names—this column
and the country column in our gapminder data
set will be our key columns; R will use them to figure
out which rows across the two data sets are related (i.e.,
they’ll share the same values in their country
columns).
We can make such a data set using the countrycode
package, so let’s install that package (if you don’t already have it),
turn it on, and check it out:
R
install.packages("countrycode") #ONLY RUN ONCE, ONLY IF YOU DON'T ALREADY HAVE THIS PACKAGE
OUTPUT
The following package(s) will be installed:
- countrycode [1.6.1]
These packages will be installed into "~/work/r-novice-gapminder/r-novice-gapminder/renv/profiles/lesson-requirements/renv/library/linux-ubuntu-jammy/R-4.4/x86_64-pc-linux-gnu".
# Installing packages --------------------------------------------------------
- Installing countrycode ... OK [linked from cache]
Successfully installed 1 package in 4.3 milliseconds.R
library(countrycode) #TURN ON THIS PACKAGE'S TOOLS
country_abbrs = countrycode(unique(gap$country), #LOOK UP ALL THE DIFFERENT GAPMINDER COUNTRIES IN THE countrycode DATABASE
"country.name", #FIND EACH COUNTRY'S NAME IN THIS DATABASE'S country.name COLUMN
"iso3c") #RETRIEVE EACH COUNTRY'S 3-LETTER ABBREVIATION
#COMPILE COUNTRY NAMES AND CODES INTO A NEW DATA FRAME
country_codes = data.frame(country = unique(gap$country),
abbr = country_abbrs)
head(country_codes)
OUTPUT
country abbr
1 Afghanistan AFG
2 Albania ALB
3 Algeria DZA
4 Angola AGO
5 Argentina ARG
6 Australia AUSThe data set we just constructed, country_codes,
contains 142 rows, one row per country found in our
gapminder data set. Each row contains a country name in the
country column and that country’s universally accepted
three-letter country code in the abbr column.
Now we can use left_join() to add that country code
abbreviation data to our gapminder data set, which doesn’t
already have it:
R
gap_joined = left_join(gap, country_codes, #THE "LEFT" TABLE GOES FIRST, AND THE "RIGHT" TABLE GOES SECOND
by = "country") #WHAT COLUMNS ARE OUR KEY COLUMNS?
head(gap_joined)
OUTPUT
country continent year lifeExp pop gdpPercap abbr
1 Afghanistan Asia 1952 28.801 8425333 779.4453 AFG
2 Afghanistan Asia 1957 30.332 9240934 820.8530 AFG
3 Afghanistan Asia 1962 31.997 10267083 853.1007 AFG
4 Afghanistan Asia 1967 34.020 11537966 836.1971 AFG
5 Afghanistan Asia 1972 36.088 13079460 739.9811 AFG
6 Afghanistan Asia 1977 38.438 14880372 786.1134 AFGHere’s what happened in this join:
R looked at the left-hand table and found all the unique values in its key column,
country.Then, for each unique value it found, it scanned the right-hand table’s key column (also called
country) for matches. Does any row over here on the right contain acountryvalue that matches thecountryvalue I’m looking for in the left-hand table?Whenever it found a match (e.g., a left-hand row and a right-hand row were both found to contain
"Switzerland"), then R asked “What stuff exists in the right-hand table’s row that isn’t already in the left-hand table’s row?”The non-redundant stuff was then copied over to the left-hand table’s row, making it wider. In this case, that was just the
abbrcolumn.
While a little hard to wrap one’s head around, joins are a powerful way to bring multiple data structures together, provided they share enough information to link their rows meaningfully!
Key Points
- Use the
dplyrpackage to manipulate data frames in efficient, clear, and intuitive ways. - Use
select()to retain specific columns when creating subsetted data frames. - Use
filter()to create a subset by rows using logical tests to determine whether a row should be kept or gotten rid of. - Use
group_by()andsummarize()to generate summaries of categorical groups within a data set. - Use
mutate()to create new variables using old ones as inputs. - Use
rename()to rename columns. - Use
arrange()to sort your data set by one or more columns. - Use pipes (
%>%) to stringdplyrverbs together into “paragraphs.” - Remember that order matters when stringing together
dplyrverbs!
Publication-quality graphics with ggplot2
Overview
Questions
- What are the most common types of operations someone might perform on a data frame in R?
- How can you perform these operations clearly and efficiently?
Objectives
Recognize the four essential “ingredients” that go into every ggplot graph.
Map aesthetics (visual components of a graph like axis, color, size, line type, etc.) to columns of your data set or to constant values.
Contrast applying settings globally (in
ggplot()), where they will apply to every component of the graph, versus locally (within ageom_*()function), where they will apply only to that one component.Use the
scale_*()family of functions to adjust the appearance of an aesthetic, including axis/legend titles, labels, breaks, limits, colors, and more.Use
theme()to adjust the appearance of any text box, line, or rectangle in your ggplot.Understand how the order of components in a ggplot command affects the final product, including how conflicts between competing instructions get resolved.
Use faceting to divide a complex graphic into sub-panels.
Write graphs to disk as image files with the desired characteristics.
Overview
Questions
- How do scientists produce publication-quality graphs using R?
- What’s it take to build a graph “from scratch,” component by component?
- What’s it mean to “map an aesthetic?”
- Which parts of a ggplot command (both required and optional) control which aspects of plot construction? When I want to modify an aspect of my graphic, how will I narrow down which component is responsible for that aspect?
- How do I save a finished graph?
- What are some ways to put my unique “stamp” on a graph?
Objectives
Recognize the four essential “ingredients” that go into every ggplot graph.
Map aesthetics (visual components of a graph like axis, color, size, line type, etc.) to columns of your data set or to constant values.
Contrast applying settings globally (in
ggplot()), where they will apply to every component of the graph, versus locally (within ageom_*()function), where they will apply only to that one component.Use the
scale_*()family of functions to adjust the appearance of an aesthetic, including axis/legend titles, labels, breaks, limits, colors, and more.Use
theme()to adjust the appearance of any text box, line, or rectangle in your ggplot.Understand how the order of components in a ggplot command affects the final product, including how conflicts between competing instructions get resolved.
Use faceting to divide a complex graphic into sub-panels.
Write graphs to disk as image files with the desired characteristics.
Introduction
When scientists first articulate their ideas for a research project, they often do so by drawing a graph of the results they expect to observe after performing a test (a “prediction graph”). When they have acquired new data, one of the first things they often do is make graphs of those data (“exploratory graphs”). And, when it’s time to summarize and communicate project findings, graphs play a key role in those processes too. Graphs lie at the heart of the scientific process!
Base R possesses a plotting system, though it is a little rudimentary and has limited customization features. Other packages, such as lattice, have added additional graphics options to R. However, no other graphics package is as widely used nor (arguably) as powerful as ggplot2.
Based on the so-called “grammar of graphics” (the “gg” in ggplot),
ggplot2 allows R users to produce highly detailed, richly
customizable, publication-quality graphics by providing a vocabulary
with which to build a complex, bespoke graph piece by painstaking
piece.
Because graphs can take on a dizzying number of forms and
have myriad possible customizations—all of which ggplot2
makes possible—the package has a learning curve for sure! However, by
linking each component of a ggplot command (both optional and required)
to its purpose and purview, we can learn to view building a ggplot as
little different from building a pizza, and nearly everyone can build
one of those!
After all, the idea at the heart of ggplot2 is that a
graph, no matter the type or style or complexity, should be
buildable using the same general set of tools and workflow,
even if there are modest and particular deviations required. Once we
understand those tools and that workflow, we’ll be well on our way to
producing graphs as stellar as those we see in our favorite
publications!
The four required components of every ggplot graph
Let’s begin by introducing the four required components every
ggplot2 graph must have. These are:
A
ggplot()call.A geometry layer.
A data frame (or tibble, or equivalent) of data to graph.
Mapping one or more aesthetics.
The first of these is, arguably, the most essential—nothing will happen without it. Let’s see what it does:
R
ggplot()
When you run this command, you should see a blank, gray window appear in your RStudio Viewer pane (or, perhaps, elsewhere, depending upon your settings):

The ggplot() function creates an empty “plotting
window,” a container that can eventually hold the plot we
intend to create. By analogy, if building a ggplot is like building a
pizza, the ggplot() call creates the crust, the first and
bottom-most layer, without which a pizza cannot really exist at all.
The other purpose of the ggplot() call is to allow us to
set global settings for our ggplot. However, let’s come
back to that idea a little later.
In the meantime, let’s move on to the second essential component of a ggplot: a data set. It should hopefully make sense that, without data, there can be no graph!
So, we need to provide data as inputs to our ggplot command somehow. We actually have options for this. We could:
Provide our data set as the first input to
ggplot()(the “standard” way), orProvide our data set as the first input to one (or more) of the
geom_*()functions we’ll add to our command.
For this lesson, we’ll always add our data via
ggplot(), but, later, I’ll mention why you might
considering doing things the “non-standard” way sometimes.
For now, let’s provide our gapminder data set to our
ggpl``ot() call’s first parameter, data:
R
ggplot(data = gap)

You’ll notice nothing has changed—our window is still empty. This should actually make sense; we’ve told R what data we want to graph, but not which exact data, where we want them, or how we want them drawn. In our pizza-building analogy, we’ve shown R the pantry and refrigerator and utensil drawers, full of available toppings and tools, but we haven’t requested anything specific yet.
Callout
Notice that the first parameter slot in ggplot() (and in
the geom_*() functions as well) is the slot for our
data set. This is purposeful; ggplot() can
accept the final product of a dplyr “paragraph” built using
pipes!
The third requirement of every ggplot is that we need to map one or more aesthetics. This is a fancy way of saying “This is thedata to graph and this is where to put them (although”where” here is not always the perfect word, as we’ll see).”
For example, when we want to plot the data found in a specific column
of our data set (e.g., those in the lifeExp
column), we communicate this to R by linking (mapping)
that column’s name to the name of the appropriate aesthetic of our
graph. We do this using the aes() function, which expects
us to use aesthetic = column name format.
This’ll be clearer with an example. Let’s make a
scatterplot of each country’s GDP per capita
(gdpPercap) on the x-axis versus its life expectancy
(lifeExp) value on the y-axis. Here’s how we can do
this:
R
ggplot(data = gap,
mapping = aes(x = gdpPercap, y = lifeExp)) #<-USE AESTHETIC = COLUMN NAME FORMAT INSIDE aes()
With this addition, our graph looks very different—we now have axes, axes labels, axes titles, grid lines, etc. This is because R now knows which data in our data set to plot and which aesthetics (“dimensions”) we want them linked to (here, the x- and y-axes).
In our pizza-building analogy, you can think of aesthetics mapping as the “sauce.” It’s another base layer that is necessary and fundamentally ties the final product together, but more is needed before we have a complete, servable product.
What’s still missing? R knows what data it should plot now and where, but still isn’t plotting them. That’s because it doesn’t know how we want them plotted. Consider that we could represent the same raw data on a graph using many different shapes (or “geometries”): points, lines, boxes, bars, wedges, and so forth. So far as R knows, we could be aiming for a scatterplot here, but we could also be aiming for a line graph, or a boxplot, or some other format.
Clearing up this ambiguity is what our geom_*()
functions are for, the fourth and final required component of a ggplot.
They specify the geometry (shape) we want the data to
take. Because we’re trying to build a scatterplot of
points, we will add the geom_point()
function to our command. Note that we literally add
this call—ggplot2 uniquely uses the + operator
to add components to the same ggplot command, somewhat similar to how
dplyr tacks multiple commands together into a single
command with the pipe operator:
R
ggplot(data = gap,
mapping = aes(x = gdpPercap, y = lifeExp)) + #<--NOTE THE + OPERATOR
geom_point()
Now that we’ve added all four essential components to our command, we finally receive a complete (albeit basic) scatterplot of GDP versus life expectancy. In our pizza-building analogy, adding one (or more) geometries (or geoms for short) is like adding cheese to the pizza. Sure, we could add more to a pizza than just cheese and do more things to make it much fancier, but a basic cheese pizza is a complete product we could eat if we wanted!
Challenge
Modify the previous command to produce a scatterplot that shows how life expectancy changes over time instead.
The gapminder data set has a column, year,
containing time data. We can swap that column in for
gdpPercap for the x aesthetic inside of our
aes() function to achieve this goal:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp)) + #<--SWAP X VARIABLE
geom_point()
This shows that even just understanding the required components of a ggplot command allows you to make tons of different graphs by mixing and matching inputs!
Challenge
Another popular ggplot aesthetic that can be
mapped to a specific column is color (why
“where” isn’t always the best term for describing aesthetics…thinking of
them as “dimensions” is probably more accurate!).
Modify the code from the previous exercise so that points are colored
according to continent.
We can add a color input to our aes() call
using aesthetic = column format like so:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, color = continent)) + #<--ADD THIRD AESTHETIC
geom_point()
This graph now shows that, while countries in Europe
tend to have high life expectancy values, the values of countries in
Africa tend to be lower, so this one modification
has added considerable value and interest to our plot.
There are dozens of aesthetics that can be mapped within
ggplot2 besides x, y, and
color, including fill, group,
z (for 3D graphs), size, alpha
(transparency), linetype, linewidth, and many
more.
Getting a little fancy
If we can create a very different graph just by adding or subtracting an aesthetic or swapping an existing aesthetic for another, it stands to reason that we can also create a very different graph by swapping the geom(s) we’re using.
Because it doesn’t actually make a lot of sense to examine changes
over time using a scatterplot, let’s change to a line graph instead.
This drastic conceptual change requires only a small
coding change; we swap geom_point() for
geom_line():
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, color = continent)) +
geom_line() #<-SWAP GEOMS
This is a very different graph than the previous one! In our pizza-building analogy, adjusting geoms is like adjusting the cheese you’re topping the pizza with. Ricotta and Parmesan and Mozzarella (and blends of these) are all very different and yield pizzas with very different “flairs,” even though the result is still a cheese pizza.
Discussion
Now, admittedly, our graph looks a little…odd. It’s probably not
immediately obvious just from looking at it, but R is currently
connecting every data point from each continent, regardless
of country, with a single line. Why do you think it’s doing that?
It’s doing this because we have specified a grouping
aesthetic—color. That is, we have mapped an
aesthetic, color, to a variable in our data set that is
categorical (or discrete) in nature rather than continuous (numeric).
When we do that, we explicitly ask R to divide our data into discrete
groups for that aesthetic. It will then assume it should do the same for
any other aesthetics or features where that same division makes
sense.
So, when R goes to draw lines, it thinks “Hmm, if they want discrete colors by continent, maybe they also want discrete lines by continent too.”
Conceptually, it probably makes more sense to think about how life
expectancy is changing per country, not per
continent, even though it still might be interesting to
consider how countries from different continents compare.
Is there a way to keep the colors as they are but separate the lines by
country?
Yes! If you want to group in one way for one aesthetic
(e.g., different colors for different continents)
but in a different way for all other aesthetics (e.g., have one
line ber country), we can make this distinction using the
group aesthetic. A ggplot will group according to the
group aesthetic for every aesthetic not explicitly grouped
in some other way:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp,
color = continent, group = country)) + #GROUP BY COUNTRY FOR EVERYTHING BUT COLOR
geom_line()
Now, we have a separate line for each country, which is probably what we were expecting to receive in the first place and is also a more nuanced way to look at the data than what we had before.
Earlier, I noted that while it’s possible to have a pizza with just one kind of cheese, you can also have a pizza featuring a blend of cheeses. Similarly, you can produce a ggplot with a blend of geoms. Let’s add points back to this graph to see this:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp,
color = continent, group = country)) +
geom_line() +
geom_point() #CAN HAVE MULTIPLE GEOMS
This graph now features both the lines and the points they connect. Is this better, or is it just busier? That’s for you to decide!
Challenge
Before we move on, there are two more aesthetics I want you to try
out: size and alpha. Try mapping
size to the pop column. Then, try mapping
alpha to a constant value of 0.3 (its default
value is 1 and it must range between 0 to
1). Remove the geom_line() call from your code
for now to make the effects of each change easier to see. What does each
of these aesthetics do?
size controls the size of the points plotted (the
equivalent for lines is linewidth):
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp,
color = continent, group = country,
size = pop)) + #ADD SIZE AND LINK IT TO POPULATION
# geom_line() +
geom_point()
Now, countries with bigger population values also have larger points. This would now be called a bubble plot, and it’s one of my all-time favorite graph types!
Meanwhile, alpha controls the transparency of
elements, with lower values being more transparent:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp,
color = continent, group = country,
alpha = 0.3)) + #SWAP FOR ALPHA
# geom_line() +
geom_point()
The effect is subtle here, but individual points are now pretty faint. Where there are many points in the same location, however, they stack on top of each other and add their alphas, resulting in a more opaque-looking dot. This allows viewers to still get a sense of “point density” even when many points would otherwise be plotted in the exact same place.
Further, when multiple points of different colors are
stacked together, their colors blend, making it more obvious
which points are stacking. As such, adjusting
alpha is a great way to add depth and nuance to a graph
that might be too “busy” to afford much otherwise!
Global vs local settings, order effects, and mapping aesthetics to constants
Perhaps you don’t like the fact that the points are also colored by continent—you’d prefer them to just be all black. However, you’d like to keep the lines colored as they are. Is this achievable?
Yes! In fact, we actually have two options to achieve it, and they relate to the two ways we can map aesthetics:
We can map a column’s data to a specific aesthetic using the
aes()function, orWe can map an aesthetic to a constant value.
Up til now, we’ve only done the first. However, here, one way to
achieve our desired outcome is to do the second. Inside
geom_point(), we could set the color aesthetic to the
constant value "black":
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp,
color = continent, group = country)) +
geom_line() +
geom_point(color = "black") #OVERRIDE THE COLOR RULES FOR THIS GEOM ONLY, SETTING THIS VALUE TO A CONSTANT
Now our points are black, but our lines remain colored by continent. Why does this work?
Callout
There are two key ggplot2 concepts revealed by this
example:
When you want to set an aesthetic to a specific, constant value, you don’t need to use the
aes()function (although we can–it’d work either way). Instead, you can simply use aesthetic = constant format.When an aesthetic has been mapped twice such that there’s a conflict (we’ve set the color of points to both
continentand to"black"here), the second mapping takes precedence. Because our second mapping setting point color to"black", that’s what happens.
However, this was not the only way to achieve this outcome. Because
"black" is the default color value already, and because we
want colors to be mapped to continents for
only our lines, we could instead map the color
aesthetic to continents just inside
geom_line(), like this:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) + #MOVE MAPPING OF THIS ONE AESTHETIC TO THE GEOM SO IT'LL ONLY APPLY THERE.
geom_point()
Callout
This approach, though quite different-looking, has the same net
effect: Our lines are colored by continent, but our points
remain black (the default). This demonstrates a third key
ggplot2 concept: Data sets can be provided, and aesthetics
can be mapped, either “globally” inside of ggplot() or else
“locally” inside of a geom_*() function.
In other words, if we do something inside ggplot(), that
thing will apply to every (relevant) component of our graph.
For example, by providing our data set inside ggplot(),
every subsequent component (our aes() calls, our
geom_point(), and our geom_line()) all assume
we are referencing that one data set.
Instead, we could provide one data set to geom_point()
and a completely different one to geom_line(), if
we wanted to (i.e., we could provide data “locally”). Each geom
would then use only the data it was provided. So long as the
two data sets are compatible enough, R’ll find a way to render
both layers on the same graph!
By managing which information we provide “globally” versus “locally,” we can heavily customize how we want our graph to look (its aesthetics) and the data each component references. In our pizza-building analogy, this is like how cheese and toppings can either be applied to the whole pizza evenly or in differing amounts for each “half” or “quarter,” if we want each slice of our pizza to be a different experience!
Challenge
There’s another key ggplot2 concept to learn at this
stage. Compare the graph above to the one produced by the code
below:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_point() +
geom_line(mapping = aes(color = continent))
In what way does this graph look different than the previous one? Why does it look different?
This second graph looks different in that our points are now underneath our lines whereas, before, they were on top of our lines.
The reason behind this difference is that we’ve swapped the order of
our geom_*() calls. Before, we called
geom_point() second; now, we’re calling it first.
This matters because ggplot2 adds layers of information
to our graph (such as our geoms) in the order in which those layers are
specified in the command, with earlier layers going on the “bottom” and
later layers going “on top.” By specifying geom_line()
second, we have instructed R to first plot points,
then plot lines, covering up the points beneath wherever
relevant.
In our pizza-building analogy, this is the same as when toppings are added—order matters! If we add pepperoni first, then cheese, our pepperoni will be present, but it’ll be buried and not visible. If we add it second, though, it’ll be visible (and less cheese will be), but it could also burn! So, which approach is better depends on the circumstances and on your preferences as well.
Customizing our aesthetics using the style_*() functions
Already, we know quite a lot about how to make an impressive ggplot!
However, there may still be several design aspects of our graph we may find dissatisfying. For example, the axes and legend titles look exactly like the names of the columns in our data set instead of something more polished. How can we change those?
Well, we could change the column names in our data set to
something more polished, which would fix the problem, but we don’t
have to do that. Whenever we want to adjust the look
of one of our graph’s mapped aesthetics, especially the axes and the
legend, we can use a scale_*() family function.
If you go to your R Console and start typing scale_ and
wait, a pop-up will appear that contains dozens and dozens of functions
that all start with scale_. There are a lot of
these functions! Which ones do we need to use?
Thankfully, all these functions follow the same naming convention, making choosing the right one less of a chore: scale_[aesthetic]_[datatype]. The second word in the function name clarifies which aesthetic we are trying to adjust and the third word clarifies what type of data is currently mapped to that aesthetic (R can’t do the exact same things to a grouping aesthetic as it would for a continuous one, e.g.).
For example, say that we wanted to reformat our x-axis’ title.
Because the x axis is mapped to continuous data, we can use the
scale_x_continuous() function to adjust its appearance.
This function’s first parameter, name, is the name we want
to use for this axis’ title:
R
#REMOVE geom_point() FOR SIMPLICITY!
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year") #<-SPECIFY NEW AXIS TITLE
Our x-axis title is now more polished-looking—even just having a capital letter makes a difference!
Challenge
Modify the code above to replace the y-axis’ title with
"Life expectancy (years)".
Our y data are also continuous, so we can use the
scale_y_continuous() function to adjust this axis’
title:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year") +
scale_y_continuous(name = "Life expectancy (years)") #WE CAN USE AS MANY SCALE FUNCTIONS AS WE WANT IN A SINGLE COMMAND.
We can do something similar for the legend title. However, because
our legend is clarifying the different colors on the graph, we
have to use a scale_color_*() function this time. Also,
this aesthetic is mapped to grouping (or categorical, or
discrete) data, so we’ll need to use the
scale_color_discrete() function:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year") +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent")
The scale_*() functions can also be used to adjust axis
labels, axis limits, legend keys, colors, and more.
For example, have you noticed that the x axis labels run from 1950 to 2000, leaving a large gap between the last label and the right edge of the graph? I personally find that gap unattractive. We can eliminate it by first expanding the limits of the x-axis out to 2010:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year", limits = c(1950, 2010)) + #MIX, MAX
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent")
This automatically adjusts the breaks of the axis (at what values the labels get put), which actually makes the problem worse! However, we can then add a set of custom breaks to tell R exactly where it should put labels on the x-axis:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2010)) + #HOW MANY LABELS, AND WHERE?
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent")
You can specify as many (or as few) breaks as you’d like, and they
don’t have to be equidistant! Further, while
breaks affects where the labels occur, the
labels parameter can additionally affect what they
say, including making them text instead of numbers. So, we
could do something kind of wild like this:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010), #ADD 2000 AS A BREAK
labels = c(1950, 1970, 1990, "Y2K", 2010)) + #MAKE ITS LABEL "Y2K"
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent")
There are so many more things that each scale_*()
function can do! Check their help pages for more details:
R
?scale_x_continuous()
As one final example, note that we can also use
scale_color_discrete() to specify new colors for our graph
to use for its continent groupings:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010), #ADD 2000
labels = c(1950, 1970, 1990, "Y2K", 2010)) + #CALL IT "Y2K"
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent",
type = c("plum", "gold", "slateblue2", "chocolate2", "lightskyblue")) #WHY THIS PARAMETER IS CALLED TYPE IS A MYSTERY :)
Let’s just hope you have better taste in colors than I do! 😂
Customizing lines, rectangles, and text using theme()
You may also have noticed that our graph’s background is gray with
white grid lines, our text is rather small, and our x- and y-axes are
missing lines. Because each of these components is a line, a text box,
or a rectangle, they fall under the purview of the theme()
function.
At the RStudio Console, type theme() and hit tab while
your cursor is inside of theme()’s parentheses. A popup
will appear that shows all the parameters that
theme() has. It’s a lot! All of these correspond
to text-based, rectangular, and linear components of your graph that you
can modify the appearance of using theme(). Half the battle
of using theme() properly, then, is just figuring out the
name of the component you’re trying to adjust!
Let’s start with those grid lines in the background. In general,
publication-quality graphics don’t have grid lines, even though
ggplot2 adds them by default, so let’s remove them. Inside
of theme(), the major grid lines are controlled by the
panel.grid.major parameter, and, to remove an element like
these from a graph, we can assign its parameter a call to the
element_blank() function:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid.major = element_blank()) #THIS ELIMINATES THIS ASPECT OF THE GRAPH
…Unfortunately, ggplots come with both major and minor grid lines, so we have to eliminate the latter also:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
Alternatively, the major and minor grid lines are also jointly
controlled by the panel.grid parameter—setting this one to
element_blank() would remove both at once:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank())
This emphasizes a general rule with theme(): Often,
there are parameters that control individual elements (such as just the
x-axis or y-axis line) and also parameters that control whole groups of
elements (such as all the axis lines at once).
For example, if we want to increase the size of all the text
in the graph, we can use the text parameter. Because all
the text in our graph is, well, text, we modify it by using the
element_text() function:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16)) #WE PUT OUR NEW SPECIFICATIONS INSIDE THE element_*() FUNCTION
OUTPUT
Scale for colour is already present.
Adding another scale for colour, which will replace the existing scale.
Now our text is much more readable for those with impaired vision!
However, if we wanted to further increase the size of just the axis
title text and also make it bold, we could again use
element_text() but target the axis.title
parameter, which targets just those two text boxes and no others:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16),
axis.title = element_text(size = 18, face = "bold")) #ANY CONFLICTS GET "WON" BY THE LAST RULE SET.
Next, what if we don’t care for the gray background on our graph?
Because that’s a rectangle, we can control it using the
element_rect() function, and the parameter in charge of
that rectangle is panel.background:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16),
axis.title = element_text(size = 18, face = "bold"),
panel.background = element_rect(fill = "white"))
That looks cleaner to me! But it still feels very odd for there to be
no x- and y-axis lines. Let’s add some! Because those lines are, well,
lines, we can control those using the
element_line() function, and the parameter in control of
both lines together is axis.line:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16),
axis.title = element_text(size = 18, face = "bold"),
panel.background = element_rect(fill = "white"),
axis.line = element_line(linewidth = 1.5, color = "black"))
Though there are many other things I would consider adjusting, this is starting to look more polished to me!
Because nearly every ggplot has textual, rectangular, and linear
elements in more or less the same places and serving more or less the
same functions, I recommend crafting a single theme() call
that you save in a separate file and reuse over and over again to style
every ggplot you create. That way, you don’t need to recreate
theme() calls each time (they can get long!), and each of
your graphs will look more similar to each other if you use a similar
design aesthetic each time.
And, if you ever encounter a scenario where your general
theme() is causing problems with a specific aspect
of a specific graph, remember our key concept from earlier:
whenever there’s a conflict for a given aesthetic, the latter rule takes
precedence.
For example, if you normally prefer to not have grid lines,
but you would prefer to have major x-axis grid lines for
this graph, you could apply your general theme first and then
add a second theme() call that contains the specific
adjustment you want to make:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16),
axis.title = element_text(size = 18, face = "bold"),
panel.background = element_rect(fill = "white"),
axis.line = element_line(linewidth = 1.5, color = "black")) +
theme(panel.grid.major.x = element_line(linetype = 'dashed')) #OVERRIDE (PART OF) THE PANEL.GRID AESTHETICS PREVIOUSLY SET.
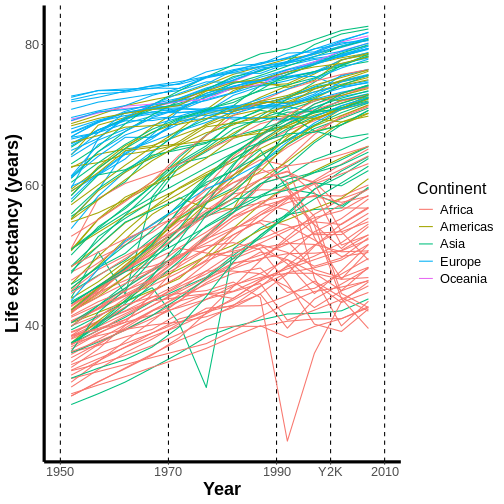
In this case, our second aesthetic command relating to grid lines conflicted with the first and overrode it to the extent necessary.
Faceting and exporting
We’ll cover two more important ggplot2 features in this
lesson. The first is faceting. This is where we take a
grouping variable and, instead of using an aesthetic to differentiate
between groups (e.g., using different colors for different
continents), we instead split our one graph into several sub-panels, one
panel per group.
For example, here’s how we could use the facet_wrap()
function to create five sub-panels of our graph, with each continent now
getting its own panel:
R
ggplot(data = gap,
mapping = aes(x = year, y = lifeExp, group = country)) +
geom_line(mapping = aes(color = continent)) +
scale_x_continuous(name = "Year",
limits = c(1950, 2010),
breaks = c(1950, 1970, 1990, 2000, 2010),
labels = c(1950, 1970, 1990, "Y2K", 2010)) +
scale_y_continuous(name = "Life expectancy (years)") +
scale_color_discrete(name = "Continent") +
theme(panel.grid = element_blank(),
text = element_text(size = 16),
axis.title = element_text(size = 18, face = "bold"),
panel.background = element_rect(fill = "white"),
axis.line = element_line(linewidth = 1.5, color = "black")) +
theme(panel.grid.major.x = element_line(linetype = 'dashed')) +
facet_wrap(facets = ~ continent) #NOTE THE ~ OPERATOR, WHICH MEANS "BY."
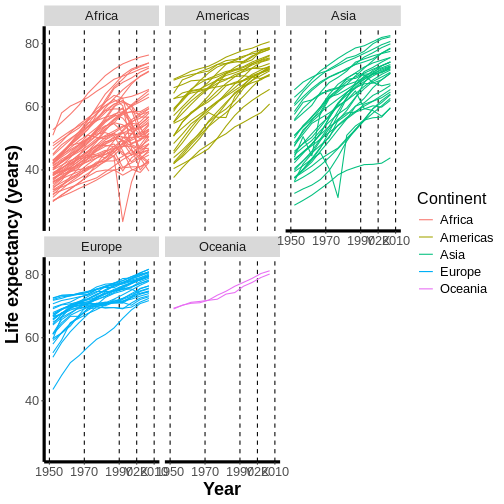
Here, we’ve created five different panels that all share similar aesthetics and characteristics, including a shared legend, uniform axes, and other key similarities. No more assembling multiple sub-panels into one figure manually in PowerPoint (we all know you’ve been doing that)!
If you don’t care for the way the facets get arranged by default, the
related facet_grid() function can be used to arrange them
in a specific way, such as in a 3 rows x 2 columns system instead.
Note the use of the ~ operator in the code above. In
faceting, ~ is used to mean “by,” so, in this case, we are
faceting by continent.
Once you have a really cool graph like this one, you might want to share it. So, your next question is likely to be “how do I save this?”
There are three ways to save a ggplot:
The first is to hit the “Export” button on the Plots panel in the lower-right of your RStudio window. On the screen that appears, you can specify a file name, a format, a size, an aspect ratio, and a destination location, as well as preview the final product. This option is convenient and reproducible, but it’s not programmatic—you’d need to do it manually every time you want to save a new version of your graph rather than writing code to have R do it for you.
The second option is to use R’s built-in image-exporting functions.
For example, if you want to save a specific graph as a .png
file, you could do the following:
R
#CREATE A PLOTTING WINDOW OF THE RIGHT SIZE, AND PRESET A FILE NAME.
png(filename = "plot1.png", width = 400, height = 600, units = "px")
#CALL THE PLOT TO PLACE IT IN THE PLOTTING WINDOW, WHICH'LL ALSO SAVE IT.
plot1
#THEN, TERMINATE THE PLOTTING WINDOW.
dev.off()
This option certainly works, but it’s tedious, and you won’t know if the product will look good until after you’ve save it and opened the new file, so this approach requires some trial and error.
The third option is to use the ggsave() function. This
function works similarly to the approach above in that you can specify a
width and height, but you can also specify a
dpi in case you need your figure to have a certain
resolution. You can also pick a wide range of output file types, which
you specify just through the filename you provide in the
call:
R
ggsave(filename = "results/lifeExp.png", #THE OUTPUT WILL BE A .PNG FILE.
plot = lifeExp_plot, #IF YOU OMIT THIS INPUT, THE LAST PLOT RENDERED WILL BE SAVED.
width = 12,
height = 10,
units = "cm",
dpi = 300)
This lesson was designed to be just a taste of what you can do with
ggplot2. RStudio provides a really useful cheat
sheet of the different layers available, and more extensive
documentation is available on the ggplot2 website. All
RStudio cheat sheets are available from the RStudio
website. Finally, if you have no idea how to change something, a
quick Google search (or ChatGPT query) will usually send you in the
right direction!
Key Points
Every ggplot graph requires a
ggplot()call, a data set, some mapped aesthetics, and one or more geometries. Mixing and matching data and their types, aesthetics, and geometries can result in a near-infinite number of different base graphs.Mapping an aesthetic means linking a visual component of your graph, such as colors or a specific axis, to either a column of data in your data set or to a constant value. To do the former, you must use the
aes()function. To do the latter, you can useaes(), but you don’t need to.Aesthetics can be mapped (and data sets provided) globally within the
ggplot()call, in which case they will apply to all map components, or locally within individualgeom_*()calls, in which case they will apply only to that element.If you want to adjust the appearance of any aesthetic, use the appropriate
scale_*()family function.If you want to adjust the appearance of any text box, line, or rectangle, use the
theme()function, the proper parameter, and the appropriateelement_*()function.In ggplot commands, the
+operator is used to (literally) add additional components or layers to a graph. If multiple layers are added, the layers added later in the command will appear on top of layers specified earlier in the command and may cover them up. If multiple, conflicting specifications are given for a property in the same ggplot command, whichever specification is given later will “win out.”Craft a single
theme()command you can use to provide consistent base styling for every one of your graphs!Use faceting to automatically create a series of sub-panels, one for each member of a grouping variable, that will share the same aesthetics and design properties.
Use the
ggsave()function to programmatically save ggplots as image files with the desired resolution, size, and file type.
Pivoting data frames with the tidyr package
Overview
Questions
- How do scientists produce publication-quality graphs using R?
- What’s it take to build a graph “from scratch,” component by component?
- What’s it mean to “map an aesthetic?”
- Which parts of a ggplot command (both required and optional) control which aspects of plot construction? When I want to modify an aspect of my graphic, how will I narrow down which component is responsible for that aspect?
- How do I save a finished graph?
- What are some ways to put my unique “stamp” on a graph?
Objectives
Distinguish between “long” and “wide” formats for storing the same data in a rectangular form.
Convert a data frame between ‘longer’ and ‘wider’ formats using the
pivot_*()functions intidyr.Appreciate that “longness” and “wideness” are a continuum and that data frames can be “long” in some respects and “wide” in others.
Anticipate the most seamless data storage format to use within your own workflows.
Overview
Questions
- Wait, there are different ways to store the same data in a rectangular form? What are they? What are their advantages and disadvantages?
- What do we really mean when we say that our data are “long” or “wide?”
- How do I make my data structure “longer” or “wider?”
Objectives
Distinguish between “long” and “wide” formats for storing the same data in a rectangular form.
Convert a data frame between ‘longer’ and ‘wider’ formats using the
pivot_*()functions intidyr.Appreciate that “longness” and “wideness” are a continuum and that data frames can be “long” in some respects and “wide” in others.
Anticipate the most seamless data storage format to use within your own workflows.
Introduction
Callout
Important: There is no one “right” way to store data in a table! There are many advantages and disadvantages to each way and, in some ways, so long as your organizational system follows good data science storage conventions, is consistent, and works for you and your team, then you’re storing your data “right.”
That said, from a computing standpoint, there are two broad ways to think about how the same data can be stored in a table: in “wide” format or in “long” format.
Imagine you had stats from several basketball teams, include the numbers of points, assists, and rebounds each team earned in their most recent game. You could store the exact same data in two very different ways:

In “wide” format, each row is usually a grouping, site, or individual for which multiple observations were recorded, and each column is everything you know about that entity, perhaps at several different times.
In “long” format, each row is a single observation (even if you have several observations per group/site/individual), and the columns serve to clarify which entity or entities each observation belongs to.
Regardless, the exact same information is being stored—it’s just arranged and conveyed differently!
Note that, when I say “long” and “wide,” I don’t mean in the physical sense related to how much data you’re storing. Obviously, if you have a lot of data, you’re going to have a lot of rows and/or columns, so your data set could look “long” even though it’s actually organized in a “wide” format and vice versa.
Discussion
Important: One consequence of data organization is that it influences how easy (or difficult!) it’ll be to use a programming language like R to manipulate your data.
Consider: How would you use dplyr’s
mutate() function to calculate a “points per rebound” value
for each team using the “wide” format data set shown above? How about
for the “long” format data set?
Then, consider: How would you use dplyr’s
summarize() function to get an average number of assists
across all teams using the “wide” format data set shown above? How about
the “long” format data set?
With the data in “wide” format, using mutate() to
calculate “points per rebound” for each team would be easy because the
two values for each team (Points and Rebounds)
are in the same row. So, we’d do something like this:
R
dataset %>%
mutate(pts_per_rebound = Points/Rebounds)
However, with the data in “long” format, it’s not at all
obvious how (or even if) one could use mutate() to get what
we want. The numbers we’re trying to slam together are in different rows
in this format, and mutate is a “row-focused” tool—it’s designed for
leveraging data being stored more “widely.”
Similarly, with the data in “wide” format, using
summarize() to calculate an average number of
Assists across all teams would be easy because all the
numbers we’re trying to smash together are in the same column.
So, we’d do something like this:
R
dataset %>%
summarize(mean_assists = mean(Assists))
Callout
Yes, you can use summarize() without using
group_by() if you don’t want to create a summary separately
for each member of a group (or if you have no groups to group by!).
However, once again, the “long” format version presents difficulties.
There are numbers in the Value column we’d need to avoid
here to calculate our average. So, it’d require us to use
filter() first to remove these:
R
dataset %>%
filter(Variable == Assists) %>% #Notice I have to filter by the Variable column...
summarize(mean_assists = mean(Value)) #...But take the mean of the Value column.
So, summarize() seems like a tool also designed
for “wide” format data, but that’s only because our wide-format
data have already been grouped by team. In fact,
group_by() and summarize() are best thought of
as tools designed to work best with “long” format data because we need
to be able to easily sub-divide our data into groups to then be able to
summarize them effectively, and long formats tend to have more “grouping
variables” to help us do that.
This whole exercise is designed to show you that while, to some extent, data organization is “personal preference,” it also has implications for how we manipulate our data (and how easy or hard it will be to do so).
While this is perhaps over-generalizing, I would say that humans tend to prefer reading and recording data in “wider” formats. When we report data in tables or record data on data sheets, we tend to do so across rows rather than down columns. Recording data in long format, in particular, tends to feel tedious because it requires us to fill out “grouping variable” data many times with much of the same information.
However, computers tend to “prefer” data stored in “longer”
formats (regardless of what the previous example may have led
you to believe!). Computers don’t “see” natural groupings in data like
humans can, so they count on having columns that clarify these groups
(like continent and country do in the
gapminder dataset), and those types of columns only exist
in “longer” formats. In particular, many dplyr verbs prefer
your data are in “long” format (mutate() is one exception),
and ggplot2 especially expects to receive data in
“long” format if you want to be able to map any
grouping aesthetics.
This may seem like a dilemma—we’re torn between how we’d
prefer the data to look and how R would prefer them to look.
But, remember, it’s all the same data, just arranged differently. So, it
seems like there should be a way to “reshape” our data to suit both
needs. And there is: The tidyr package’s functions
pivot_longer() and pivot_wider().
Minding the Gapminder
Discussion
Let’s take another good look at the gapminder data set
to remind ourselves of its structure:
R
head(gap)
OUTPUT
country continent year lifeExp pop gdpPercap
1 Afghanistan Asia 1952 28.801 8425333 779.4453
2 Afghanistan Asia 1957 30.332 9240934 820.8530
3 Afghanistan Asia 1962 31.997 10267083 853.1007
4 Afghanistan Asia 1967 34.020 11537966 836.1971
5 Afghanistan Asia 1972 36.088 13079460 739.9811
6 Afghanistan Asia 1977 38.438 14880372 786.1134Consider: Is the gapminder data set in “long” format or
“wide” format? Why do you say that?
Sorry, but this is sort of a trick question because the right answer is “both” (or “neither”).
On the one hand, the gapminder data set is not
as “long” as it could be. For example, right now,
there are three columns containing numeric data (pop,
lifeExp, and gdpPercap). We could
instead have a single Value column to hold all these data,
as we had with our fake sports data earlier, and a second column that
lists what kind of Value each row contains.
On the other hand, the gapminder data set is also not
as “wide” as it could be either. For example, right
now, there are three grouping variables (country,
year, and continent). We could
instead have a single row per country and then separate
columns for the data from each year (i.e.,
pop1952, pop1957, pop1962,
etc.) for each country.
Callout
So, “longness” vs. “wideness” is a spectrum, and the
gapminder data set exists sort of in the middle!
Hold onto this idea—for the rest of this lesson, we’re going to see how to make those longer and wider versions we just imagined!
PIVOT_LONGER
We’ll begin by seeing how to make our data even longer than it is now
by combining all the values in the pop,
lifeExp, and gdpPercap columns into a single
column called Value. We’ll then add a second column
(officially called a key column), a grouping column,
that clarifies which Statistic is being stored in
the Value column in that row.
The tidyr verb that corresponds with this desire is
pivot_longer(). As with most tidyverse verbs,
the first input to pivot_longer() is
always the data frame you are trying to reshape (or
pivot). In this case, that will be our
gapminder data set.
After providing our data set, we will provide three more inputs in this particular case:
The columns we are eliminating and collapsing into a single column. Here, that will be the
pop,lifeExp, andgdpPercapcolumns. We’ll provide these as inputs to thecolsparameter, specifically.The name of the new column that will hold all the values that used to be held by the columns we’re eliminating. We’ll call this new column
Value, and we’ll provide that name as the input to thevalues_toparameter.The name of the new key column that clarifies which statistic is being stored in the
Valuecolumn in a given row. We’ll call this new columnStatistic, and we’ll provide this name as the input to thenames_toparameter.
Let’s put all this together and see what it looks like!
R
gap_longer = gap %>%
pivot_longer(cols = c(pop, lifeExp, gdpPercap),
values_to = "Value",
names_to = "Statistic")
head(gap_longer)
OUTPUT
# A tibble: 6 × 5
country continent year Statistic Value
<fct> <fct> <int> <chr> <dbl>
1 Afghanistan Asia 1952 pop 8425333
2 Afghanistan Asia 1952 lifeExp 28.8
3 Afghanistan Asia 1952 gdpPercap 779.
4 Afghanistan Asia 1957 pop 9240934
5 Afghanistan Asia 1957 lifeExp 30.3
6 Afghanistan Asia 1957 gdpPercap 821. The first thing I want you to notice about our new
gap_longer object (by looking in the
‘Environment Pane’) it is indeed much longer than gap was;
it’s now up to 5112 rows! It also has one fewer column.
Challenge
The other important thing to notice is the contents of the new
Statistic column. Where did this column’s contents come
from?
It’s now storing the names of the old columns, the ones we got rid of! It figures if those names were good enough to serve as column names in the original data, they must be good enough to be grouping data in this new structure too!
PIVOT_WIDER
Now, we’ll go the other way—we’ll make our gapminder
data set wider than it already is. We’ll make a data set that has a
single row for each country (countries will be our groups)
and we’ll have a different column for every year x
“Statistic” combo we have for each country.
The tidyr verb that corresponds with this desire is
pivot_wider(), and it works very similarly to
pivot_longer(). Besides our data frame (first input), we’ll
provide pivot_wider() two inputs:
- The column(s) we’re going to eliminate by spreading their
contents out over several new columns. In our new, wider data set,
we’re going to have a column for each
yearx “Statistic” combination, so we’re going to eliminate the currentpop,lifeExp, andgdpPercapcolumns as we know them. We’ll provide these columns as inputs topivot_wider()’svalues_fromparameter, as in “take the values for these new columns from those in these old columns.” - The column that we’re going to eliminate by instead inserting it
into the names of the new columns we’re creating. Here, that’s going
to be the
yearcolumn (I promise this’ll make more sense when you see it!). We’ll provide this as an input to thenames_fromparameter, as in “take the names of the new columns from this old column’s name.”
Let’s see what this looks like:
R
gap_wider = gap %>%
pivot_wider(values_from = c(pop, lifeExp, gdpPercap),
names_from = year)
head(gap_wider)
OUTPUT
# A tibble: 6 × 38
country continent pop_1952 pop_1957 pop_1962 pop_1967 pop_1972 pop_1977
<fct> <fct> <int> <int> <int> <int> <int> <int>
1 Afghanistan Asia 8425333 9240934 10267083 11537966 13079460 14880372
2 Albania Europe 1282697 1476505 1728137 1984060 2263554 2509048
3 Algeria Africa 9279525 10270856 11000948 12760499 14760787 17152804
4 Angola Africa 4232095 4561361 4826015 5247469 5894858 6162675
5 Argentina Americas 17876956 19610538 21283783 22934225 24779799 26983828
6 Australia Oceania 8691212 9712569 10794968 11872264 13177000 14074100
# ℹ 30 more variables: pop_1982 <int>, pop_1987 <int>, pop_1992 <int>,
# pop_1997 <int>, pop_2002 <int>, pop_2007 <int>, lifeExp_1952 <dbl>,
# lifeExp_1957 <dbl>, lifeExp_1962 <dbl>, lifeExp_1967 <dbl>,
# lifeExp_1972 <dbl>, lifeExp_1977 <dbl>, lifeExp_1982 <dbl>,
# lifeExp_1987 <dbl>, lifeExp_1992 <dbl>, lifeExp_1997 <dbl>,
# lifeExp_2002 <dbl>, lifeExp_2007 <dbl>, gdpPercap_1952 <dbl>,
# gdpPercap_1957 <dbl>, gdpPercap_1962 <dbl>, gdpPercap_1967 <dbl>, …As the name suggests, gap_wider is indeed much wider
than our original gapminder data set: It has
38 columns instead of the original 6. We also
have fewer rows: Just 142 (one per country)
compared to the original 1704.
Importantly, our new columns have intuitive, predictable names:
gdpPercap_1972, pop_1992, and
lifeExp1987, etc. Hopefully this is making more
sense to you now!
Challenge
You’ve now seen both pivot_longer() and
pivot_wider(). Maybe you’ve noticed they seem like
“opposites?” They are! They’re designed to “undo” the other’s
work, in fact!
So, use pivot_wider() to “rewind”
gap_longer back to the organization of our original data
set.
This task is thankfully relatively easy. We tell R that it
should pull the names for the new columns in our wider table from the
Statistic column, then pull the values for those new
columns from the old Value column:
R
gap_returned1 = gap_longer %>%
pivot_wider(names_from = Statistic,
values_from = Value)
head(gap_returned1)
OUTPUT
# A tibble: 6 × 6
country continent year pop lifeExp gdpPercap
<fct> <fct> <int> <dbl> <dbl> <dbl>
1 Afghanistan Asia 1952 8425333 28.8 779.
2 Afghanistan Asia 1957 9240934 30.3 821.
3 Afghanistan Asia 1962 10267083 32.0 853.
4 Afghanistan Asia 1967 11537966 34.0 836.
5 Afghanistan Asia 1972 13079460 36.1 740.
6 Afghanistan Asia 1977 14880372 38.4 786.Challenge
Now, use pivot_longer() to “rewind”
gap_wider back to the organization of the original data
set. This transformation is a little more complicated; you’ll
need to specify slightly different inputs than the ones you’ve seen
before:
- For the
names_toparameter, specify exactlyc(".value", "year").".value"is a special input value here that has a particular meaning—see if you can guess what that is! Hint: You can use?pivot_longer()to research the answer, if you’d like. - You’ll also need to specify exactly
"_"as an input for thenames_sepparameter. See if you can guess why. - Lastly, you won’t need to specify anything for the
values_toparameter this time—".value"is taking care of the need to put anything there.
Here’s how we’d use pivot_longer() to “rewind” to our
original data set:
R
gap_returned2 = gap_wider %>%
pivot_longer(cols = pop_1952:gdpPercap_2007,
names_to = c(".value", "year"),
names_sep = "_")
head(gap_returned2)
OUTPUT
# A tibble: 6 × 6
country continent year pop lifeExp gdpPercap
<fct> <fct> <chr> <int> <dbl> <dbl>
1 Afghanistan Asia 1952 8425333 28.8 779.
2 Afghanistan Asia 1957 9240934 30.3 821.
3 Afghanistan Asia 1962 10267083 32.0 853.
4 Afghanistan Asia 1967 11537966 34.0 836.
5 Afghanistan Asia 1972 13079460 36.1 740.
6 Afghanistan Asia 1977 14880372 38.4 786.Our inputs for names_to were telling R “the names of the
new columns should come from the first parts of the names of
the columns we’re getting rid of.” That’s what the
".values" bit is doing!
Then, we were telling R “the other column you should make should
simply be called year.”
Lastly, by saying names_sep = "_", we were indicating
that R should hack apart the old column names at the underscores (aka
separate the old names at the _) to find the
proper bits to use in the new column names.
So, R pulled apart the old column names, creating pop,
lifeExp, and gdpPercap columns from their
front halves, and then putting the remaining years in the old column
names into the new year column. Pretty incredible,
huh??
Try to rephrase the above explanation in your own words!
Bonus: separate_*() and unite()
One of the reasons tidyr is such a useful package is
that it introduces easy pivoting to R, an operation
many researchers instead use non-coding-based programs like Microsoft
Excel to perform. While we’re on the subject of tidyr, we
thought we’d mention two other tidyr functions that can do
things you might otherwise do in Excel.
The first of these functions is unite(). It’s common to
want to take multiple columns and glue their contents together into a
single column’s worth of values (in Excel, this is called
concatenation).
For example, maybe you’d rather have a column of country names with
the relevant continent tacked on via underscores (e.g.,
"Albania_Europe").
You could produce such a column already using dplyr’s
mutate() function combined with R’s paste0()
function, which pastes together a mixture of values and text into a
single text value:
R
gap %>%
mutate(new_col = paste0(country,
"_",
continent)) %>%
select(new_col) %>%
head()
OUTPUT
new_col
1 Afghanistan_Asia
2 Afghanistan_Asia
3 Afghanistan_Asia
4 Afghanistan_Asia
5 Afghanistan_Asia
6 Afghanistan_AsiaHowever, this is approach is a little clunky.
unite() can do this same operation more cleanly and
clearly:
R
gap %>%
unite(col = "new_col", #NAME NEW COLUMN
c(country, continent), #COLUMNS TO COMBINE
sep = "_") %>% #HOW TO SEPARATE THE ORIGINAL VALUES, IF AT ALL.
select(new_col) %>%
head()
OUTPUT
new_col
1 Afghanistan_Asia
2 Afghanistan_Asia
3 Afghanistan_Asia
4 Afghanistan_Asia
5 Afghanistan_Asia
6 Afghanistan_AsiaJust as often, we want to break a single column’s contents apart
across multiple new columns. For example, maybe we want to split our
four-digit year data in two columns: one for the first two digits and
one for the last two (e.g., 1975 becomes
19 and 75).
In Excel, you might use the “Text to Columns” functionality to split a column apart like this, either at a certain number of characters or at a certain delimiter, such as a space, a comma, or an underscore.
In tidyr, we can use the separate_*()
family of functions to do this. separate_wider_delim() will
break one column into two (or more) based on a specific delimiter,
whereas separate_wider_position() will break one column
into two (or more) based on a number of characters, which is what we
want to do here:
R
gap %>%
separate_wider_position(cols = year, #COLUMN(S) TO SPLIT
widths = c("decades" = 2, "years" = 2)) %>% #NEW COLUMNS: "NAMES" = NUMBER OF CHARACTERS
select(decades, years) %>%
head()
OUTPUT
# A tibble: 6 × 2
decades years
<chr> <chr>
1 19 52
2 19 57
3 19 62
4 19 67
5 19 72
6 19 77 Performing operations like these in R instead of in Excel makes them more reproducible!
Key Points
- Use the
tidyrpackage to reshape the organization of your data. - Use
pivot_longer()to go towards a “longer” layout. - Use
pivot_wider()to go towards a “wider” layout. - Recognize that “longness” and “wideness” is a continuum and that your data may not be as “long” or as “wide” as they could be.
- Recognize that there are advantages and disadvantages to every data layout.
Content from Control Flow--if() and for()
Last updated on 2025-04-15 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- How can I get R to assess a situation and respond differently to different circumstances?
- How can I get R to repeat the same or similar operations instead of copy-pasting the same code over and over?
Objectives
- Recognize when and how to make the COMPUTER do your tedious, complex, and repetitive data tasks.
- Practice indexing and logical tests in the context of solving a frustrating data management problem.
- Demystify the structure and syntax of the dreaded “for loop.”
Intro
In this unit, we’re going to start by creating a fake and annoying data management problem that we will then get to solve easily using two powerful programming tools. Let’s create that annoying problem first.
The basic idea is that we will need to find and respond to a complex pattern in our data–something we need to do all the time when working with real data sets! So, we’ll need to generate some complex data first, which we will do using random sampling.
However, because it would be nice if we all had the same random data to work with (so we all get the same answers!), we can first use a little “cheat code.” In R, you can make random things “predictably random” by first setting a specific seed for R’s random number generator to use. Doing so will ensure we all get the same “answers,” so don’t skip this step!
R
set.seed(123) #Ensures that all random processes will "start from the same place."
Next, let’s begin by making a giant random vector full of
values. To do this, we can use the sample() function. Here,
we’ll provide sample() with three inputs: an
x, a size, and a replace. See if
you can guess what each input does!
R
rand_vec1 = sample(
x = c(0,1),
size = 10000,
replace = TRUE)
We can see the first 100 values of rand_vec1 by using
indexing.
R
rand_vec1[1:100] #Extract values 1 thru 100.
OUTPUT
[1] 0 0 0 1 0 1 1 1 0 0 1 1 1 0 1 0 1 0 0 0 0 1 0 0 0 0 1 1 0 1 0 1 0 1 1 0 0
[38] 0 0 1 0 1 1 0 0 0 0 1 0 0 1 0 0 0 0 1 1 0 1 0 0 1 1 0 0 1 0 0 0 0 1 0 0 0
[75] 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 1 1 0 1 1 0 0 1 0 0Here, we see that we drew randomly from the values 0 and 1
(x is the “pool” of values we draw from) 10,000 times
(size is the number of draws to do) with replacement
(replace = TRUE).
Let’s do the exact same thing again to create a second vector,
rand_vec2, that will be randomly different from the first
one we made.
R
rand_vec2 = sample(
x = c(0,1),
size = 10000,
replace = TRUE)
We’ll then create a data frame (table) with these two random
vectors as columns, which we’ll call a and b
for simplicity.
R
dataset1 = data.frame(a = rand_vec1,
b = rand_vec2)
Establishing our problem
Ok, now that we’ve created our “fake, random data set,” let me explain the annoying data problem involving it that we’ll need to solve.
We have two columns, a and b. Imagine that,
for our analyses, we need to create a new, third column, c,
that equals 0 except whenever the current value in column
a is equal to 1 and ALSO the previous
value in column b is also equal to 1. All
other times, c should equal 0 though.
For example, in the sample table below, the value of c
in row 2 would be 1 (column a’s second value is 1 and
column b’s first value is also 1) but 0 in row 3 (because
a’s value is 0) and row 4 (because b’s
previous value is 0):
OUTPUT
a b
1 0 1
2 1 1
3 0 0
4 1 1What an annoying pattern to have to spot, right? Finding patterns like these is something we often have to do when analyzing real-world data. Imagine trying to hunt for this pattern by eye, perhaps in Microsoft Excel, by going row by row. It’d be torture, it’d take forever, and we’d probably make a lot of mistakes.
Instead, we can “teach” R how to find this pattern for us! To do
that, though, we need to harness two powerful functions that control how
R “goes with the flow” and makes “decisions”: if() and
for().
If statements
We’ll start with if() because it’s the simpler of the
two functions to learn. Even still, if you are not an experienced
programmer, if() will probably feel very “programming-y” to
you at first.
The good news is that you have probably experienced an “if statement” in your real life! For example:

In life, we often encounter “rules.” If we pass or satisfy the rule, we get to do stuff (like ride a roller coaster) and, if we don’t pass or satisfy the rule, we have to do nothing.
if() works the exact same way! We provide it a “rule” as
an input and then also “stuff” (code) that will execute if and only if
that “rule” passes.
To see what I mean, let’s create an object called x and
set its value to a known value of 10.
R
x = 10
Now, let’s write an if() statement involving
x. In if()’s parentheses, we provide a
logical test, which consists of an object who’s value we will
check (here, that’s x), a logical operator (I’ll
use < or “less than” below), and a “benchmark” to check
that value against (below, I use the value 20).
Then, in if()’s curly braces, we put code that
should only execute if the logical test passes.
Putting all this together in the example below, I check to see if the
value of x is less than 20, which we know that
it is, so the code in the curly braces will run.
R
if(x < 20) {
print("Yes")
}
OUTPUT
[1] "Yes"What happens if the logical test fails instead? To see,
change the logical operator to “greater than”
(>) instead. What do you get, and why?
R
if(x > 20) {
print("Yes")
}
Challenge
As we’ve used it so far, if() only gets R to do
something if the logical test we’ve provided passes. What if
you wanted to do something either way (whether the test passes or
fails)–what could you do in this situation?
Your first temptation might be to put multiple if()s in
a row to catch all possible outcomes, such as by using the two
if() calls we’ve already written back to back to catch when
x is greater than 20 and when it’s less than 20. This
works, but if there are only two possible outcomes, there’s an easier
way…
If/else statements
if() has a companion function, else, that
you can pair it with so that something happens when the logical
test passes and something different happens when the
logical test fails. Here’s what this looks like:
R
if(x > 20) {
print("Yes")
} else {
print("No")
}
OUTPUT
[1] "No"In the example above, "No" gets printed. Why? Well, the
logical test failed, so R skipped over the operations given to
if() and instead executed the operations given to
else.
Notice that else gets curly braces but not
parentheses. Why? Remember that logical tests must be
mutally exclusive, meaning they are either
TRUE (they pass) or FALSE (they fail). A
single logical test can yield either outcome, so the one
logical test we give to if() can serve as the
necessary input for both if() and else.
Callout
Important: This means that an else is
fundamentally dependent on the if() it goes with.
As a result, an else must always start on the same line as
its if() ends on. For example, the code below would trigger
an error:
This is an example of how line breaks do occasionally matter in R.
For simplicity, we won’t show it here, but if you had a situation
where there were more than 2 possible outcomes and you wanted to do
something different in each one, you can stack if()s and
elses inside of each other to create as complex a “decision
tree” as you need to!
Challenge
How does knowing if() help us solve our annoying data
problem involving columns a through c that we
set up earlier, do you think?
Recall that we want the value in column c to be equal to
1 only if two specific conditions are met. So, we
can’t even talk about our data problem without using the word “if.”
That’s not an accident–if() will help us ensure that we do
the right thing whenever those conditions are met and something
else if they aren’t.
Challenge
Let’s practice trying to use if() and else
to start solving our data problem by using them to check to see what the
correct value for column c should be in row 2 of our data
set.
Write an if/else pair that checks if the SECOND value in
column a is equal to 1 (use == as
the logical operator to check for equality!) and the
FIRST value in column b is also equal to
1.
Inside your curly braces, make an object called
c and set its value to 1 if both conditions
are met and to 0 if not.
Hint: You can put two FULL logical rules inside of
if()’s parentheses and separate them with an
& (“and”) if you want if() to check
against two rules instead of just one.
Here’s what this could look like:
R
if(dataset1$a[2] == 1 &
dataset1$b[1] == 1 ) {
c = 1
} else {
c = 0
}
What happens when we run the code above–what does c
become? Let’s check:
R
print(c)
OUTPUT
[1] 0It became 0. Is that what should have happened? Let’s
look at the first two rows of our data set to confirm that our code did
what we wanted it to do:
R
dataset1[1:2, ] #Rows 1 and 2, all columns
OUTPUT
a b
1 0 0
2 0 1Yes, 0 is the right value because both
conditions we were checking against were FALSE in this
case.
Nice! We can now have R perform this kind of check for us and it will do it flawlessly every single time, unlike us humans who might mess it up sometimes!
For loops to repeat operations
If you did the challenge above (at least view the answer before
continuing!), you saw that we can use if() and
else to check whether row 2 in our data set passes both of
our conditions for when to put a 1 in column
c.
…Now, we’d just need to do this same check for the 9998 remaining rows, right? Get ready to copy-paste a lot of code!
…No, I’m just kidding! Let’s definitely not do it
that way. Instead, we should just get R to repeat this
check the rest of the times we need to do it. Fortunately, repeating
tasks is exactly what the for() function is for.
Again, if you don’t have a programming background, for()
will probably look very “programming-y” to you. However, once again, the
good news is that you have probably experienced a “real-life for loop”
at least once! For example:

If you’ve been to a deli counter that uses a ticket system like the one above, you probably already know how the system works:
Everyone who wants some meat or cheese takes a ticket with a unique number on it.
The worker behind the counter calls out the number of the next ticket, putting that number up on a display board so everyone can see which ticket we’re on.
The customer with that ticket number comes up to the counter and places their order.
The worker then processes that order in roughly the same way every time (gets the selection out, cuts it, places the slices in a baggie, cleans the slicer, etc.).
Then, the process repeats for the next customer and ticket number
until all the tickets are gone. This process of repeating the same set
of operations over and over again (even if the specifics actually change
somewhat each time!) all while keeping track of which “repeat” we’re on
is exactly how for() works too!
Let’s write out a “fake” for() call so we can see the
basic parts and how they match up with the story I just told:
for(current_ticket in pool_of_ticket_values) {
–code for R to repeat for every ticket–
}
Inside the parentheses above, we first have an object holding the
“current ticket number” that we’re on called
current_ticket. That object is exactly like the digital
“Now serving ticket #X” sign in our deli counter example.
Then, we have a connector function called in, which we
can safely ignore (as long as we don’t forget to include it!).
Then, we have another object called
pool_of_ticket_values that holds all possible ticket values
we will need to go through, one by one, until we are “done” serving our
customers.
Then, just as with if(), for() has
curly braces. Inside these, we have code that will run, from
top to bottom, the same exact way for each ticket value we draw from our
pool. In our story, these are the steps the worker goes through for each
customer. Each customer might want slightly different things, so the
“inputs” for these operations may change, but what gets done and when is
roughly the same every time.
Said differently, each time the operations inside the curly
braces begin, current_ticket will first become equal
to the next available value in the pool_of_ticket_values.
Then, all the operations inside the curly braces will run once
from top to bottom. That process will then repeat (or “loop”) until the
ticket pool is empty and there are no more new values to set
current_ticket equal to.
We can demonstrate this order of events using a working (albeit dumb) example for loop:
R
for(ticket in 1:10) {
print(
paste0("Now serving ticket number: ",
ticket)
)
}
OUTPUT
[1] "Now serving ticket number: 1"
[1] "Now serving ticket number: 2"
[1] "Now serving ticket number: 3"
[1] "Now serving ticket number: 4"
[1] "Now serving ticket number: 5"
[1] "Now serving ticket number: 6"
[1] "Now serving ticket number: 7"
[1] "Now serving ticket number: 8"
[1] "Now serving ticket number: 9"
[1] "Now serving ticket number: 10"What’s going on here? R is printing the message “Now serving ticket number: X” 10 times, with X changing each time. How did this happen?
R starts to execute this code by first taking the first value in our
pool (which here is 1), and makes ticket equal
to that value. It then executes the code in the curly braces,
which tells it to print a message.
However, specifically, we’ve asked it to use the current value of
ticket inside our message, like we’re having it read off
the “digital display board” to adjust its behavior depending on what
ticket we’re currently on. The fact that we can use
ticket inside our operations to “do work” is
important!
The process then repeats until our pool is empty, which in this case
happens after we’ve used the last value in our pool, which is
10 here.
Challenge
How does knowing for() help us solve our annoying data
challenge, do you think?
To fill out all 10,000 rows of our c column, we need to
do the same check for each row. Again, we can’t even discuss
our problem without using the word “for.” That’s not an accident! We can
use for() to repeat the check for every row and respond
accordingly even as the exact “inputs” change from one row to the
next.
Solving our annoying data challenge
We’re nearly ready to solve our frustrating data management challenge, but we just need to do a couple of preparation steps first.
Since we’re going to need a c column in our data set but
there isn’t one yet, let’s make one and fill it with NA
values to start with (since we don’t yet know what those values should
be).
R
dataset1$c = NA
The above command adds a new column called c to our data
set (if our data set already had a column called c, it
would replace that column instead). It then fills that column with
NA.
This step is called “pre-allocating.” We’re preparing a space for all
the new values we’re about to place in that c column! It’s
not strictly necessary to pre-allocate space for new stuff you want to
create using a for loop, but for loops can get
really slow if you don’t do it!
We can now build our for loop! To start, we have to pick a
name for our “current ticket” object because, as we saw in our earlier
example, it can be called whatever we want. I prefer names that have
meaning in the context of what I’m trying to accomplish. Here, because
we are repeating operations for each new row we want to
check, I will helpfully name this object current_row.
Then, I place in and then I need a pool of values that
will ensure the loop repeats the proper number of times. Because our
data set is 10,000 rows long, because we want to perform our check for
every row, and because the first row can never pass our tests
(there is no previous value for column b for row 1), we can
make our pool of the values ranging from 2 up to
10000.
R
for(current_row in 2:10000) {
#Operations will go here...
}
Inside the curly braces, I now just need to tell R to check
the appropriate values in columns a and b and
set the appropriate values in column c accordingly.
We already wrote more or less the code needed to perform this check in an earlier challenge:
R
if(dataset1$a[2] == 1 &
dataset2$b[1] == 1 ) {
c = 1
} else {
c = 0
}
The only problem is that the above code only works to check the 2nd
row of column a and the 1st row of column b.
In other words, it’s too specific–we’ll need it to be more generic here
so that it can work for whatever row of our data set we’re currently
on.
Here’s where we can take advantage of the current_row
object:
R
if(dataset1$a[current_row] == 1 &
dataset1$b[current_row-1] == 1 ) {
dataset1$c[current_row] = 1
} else {
dataset1$c[current_row] = 0
}
Now, we’re telling R “whatever the current row is,
check the appropriate values and set the value of c in that
row accordingly.” As R works through the pool of values in
2:10000, current_row will become those values,
one at a time, so it will start out being 2, then
3, and so on. So, we can use that to point R to a new row
each time through the loop!
Callout
Notice we can also do math inside square brackets to access
the previous value in column b–that’s a handy
trick!
If we put all this together, this is our final for loop:
R
for(current_row in 2:10000) {
if(dataset1$a[current_row] == 1 &
dataset1$b[current_row-1] == 1 ) {
dataset1$c[current_row] = 1
} else {
dataset1$c[current_row] = 0
}
}
And now, the all-important question: Did it work? Let’s examine the
first 20 rows–see if you can determine whether column c
looks as it should or not:
R
dataset1[1:20,]
OUTPUT
a b c
1 0 0 NA
2 0 1 0
3 0 0 0
4 1 1 0
5 0 1 0
6 1 1 1
7 1 0 1
8 1 1 0
9 0 1 0
10 0 0 0
11 1 0 0
12 1 0 0
13 1 1 0
14 0 1 0
15 1 1 1
16 0 0 0
17 1 1 0
18 0 1 0
19 0 0 0
20 0 0 0The short answer: Yes, it does! This means we just had R do literally hours of torturous work in just seconds, flawlessly, with just eight lines of code! You’ll never have to do something like this in Excel “by eye” ever again!
Challenge
Add a fourth column, d, to our data set. Set
d equal to 1 whenever the current value of
either column a or column
b is 0 and make d equal to
0 all other times. Hint: If you want to check to see if one
logical test or another passes, use
| (“or”) instead of & (“and”) to connect
the two tests.
Here’s one valid way to do this, though there are others! Don’t
forget to preallocate column d first!
R
dataset1$d = NA
for(current_row in 1:10000) { #We can check row 1 here if we want to!
if(dataset1$a[current_row] == 0 | #Note the use of the or operator, |.
dataset1$b[current_row] == 0 ) { #No need to use math in the square brackets this time.
dataset1$d[current_row] = 1
} else {
dataset1$d[current_row] = 0
}
}
Key Points
- Use
ifandelseto have R make choices on the fly for you with respect to what operations it should do. - Use
forto repeat operations many times.
Content from Vectorization
Last updated on 2025-04-15 | Edit this page
Estimated time: 25 minutes
Overview
Questions
- How can I operate on all the elements of a vector at once?
Objectives
- To understand vectorized operations in R.
Most of R’s functions are vectorized, meaning that the function will operate on all elements of a vector without needing to loop through and act on each element one at a time. This makes writing code more concise, easy to read, and less error prone.
R
x <- 1:4
x * 2
OUTPUT
[1] 2 4 6 8The multiplication happened to each element of the vector.
We can also add two vectors together:
R
y <- 6:9
x + y
OUTPUT
[1] 7 9 11 13Each element of x was added to its corresponding element
of y:
Here is how we would add two vectors together using a for loop:
R
output_vector <- c()
for (i in 1:4) {
output_vector[i] <- x[i] + y[i]
}
output_vector
OUTPUT
[1] 7 9 11 13Compare this to the output using vectorised operations.
R
sum_xy <- x + y
sum_xy
OUTPUT
[1] 7 9 11 13Challenge 1
Let’s try this on the pop column of the
gapminder dataset.
Make a new column in the gapminder data frame that
contains population in units of millions of people. Check the head or
tail of the data frame to make sure it worked.
Let’s try this on the pop column of the
gapminder dataset.
Make a new column in the gapminder data frame that
contains population in units of millions of people. Check the head or
tail of the data frame to make sure it worked.
R
gapminder$pop_millions <- gapminder$pop / 1e6
head(gapminder)
OUTPUT
country year pop continent lifeExp gdpPercap pop_millions
1 Afghanistan 1952 8425333 Asia 28.801 779.4453 8.425333
2 Afghanistan 1957 9240934 Asia 30.332 820.8530 9.240934
3 Afghanistan 1962 10267083 Asia 31.997 853.1007 10.267083
4 Afghanistan 1967 11537966 Asia 34.020 836.1971 11.537966
5 Afghanistan 1972 13079460 Asia 36.088 739.9811 13.079460
6 Afghanistan 1977 14880372 Asia 38.438 786.1134 14.880372Challenge 2
On a single graph, plot population, in millions, against year, for all countries. Do not worry about identifying which country is which.
Repeat the exercise, graphing only for China, India, and Indonesia. Again, do not worry about which is which.
Refresh your plotting skills by plotting population in millions against year.
R
ggplot(gapminder, aes(x = year, y = pop_millions)) +
geom_point()
R
countryset <- c("China","India","Indonesia")
ggplot(gapminder[gapminder$country %in% countryset,],
aes(x = year, y = pop_millions)) +
geom_point()
Comparison operators, logical operators, and many functions are also vectorized:
Comparison operators
R
x > 2
OUTPUT
[1] FALSE FALSE TRUE TRUELogical operators
R
a <- x > 3 # or, for clarity, a <- (x > 3)
a
OUTPUT
[1] FALSE FALSE FALSE TRUETip: some useful functions for logical vectors
any() will return TRUE if any
element of a vector is TRUE.all() will return TRUE if all
elements of a vector are TRUE.
Most functions also operate element-wise on vectors:
Functions
R
x <- 1:4
log(x)
OUTPUT
[1] 0.0000000 0.6931472 1.0986123 1.3862944Vectorized operations work element-wise on matrices:
R
m <- matrix(1:12, nrow=3, ncol=4)
m * -1
OUTPUT
[,1] [,2] [,3] [,4]
[1,] -1 -4 -7 -10
[2,] -2 -5 -8 -11
[3,] -3 -6 -9 -12Tip: element-wise vs. matrix multiplication
Very important: the operator * gives you element-wise
multiplication! To do matrix multiplication, we need to use the
%*% operator:
R
m %*% matrix(1, nrow=4, ncol=1)
OUTPUT
[,1]
[1,] 22
[2,] 26
[3,] 30R
matrix(1:4, nrow=1) %*% matrix(1:4, ncol=1)
OUTPUT
[,1]
[1,] 30For more on matrix algebra, see the Quick-R reference guide
Challenge 3
Given the following matrix:
R
m <- matrix(1:12, nrow=3, ncol=4)
m
OUTPUT
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12Write down what you think will happen when you run:
m ^ -1m * c(1, 0, -1)m > c(0, 20)m * c(1, 0, -1, 2)
Did you get the output you expected? If not, ask a helper!
Given the following matrix:
R
m <- matrix(1:12, nrow=3, ncol=4)
m
OUTPUT
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12Write down what you think will happen when you run:
m ^ -1
OUTPUT
[,1] [,2] [,3] [,4]
[1,] 1.0000000 0.2500000 0.1428571 0.10000000
[2,] 0.5000000 0.2000000 0.1250000 0.09090909
[3,] 0.3333333 0.1666667 0.1111111 0.08333333m * c(1, 0, -1)
OUTPUT
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 0 0 0 0
[3,] -3 -6 -9 -12m > c(0, 20)
OUTPUT
[,1] [,2] [,3] [,4]
[1,] TRUE FALSE TRUE FALSE
[2,] FALSE TRUE FALSE TRUE
[3,] TRUE FALSE TRUE FALSEChallenge 4
We’re interested in looking at the sum of the following sequence of fractions:
R
x = 1/(1^2) + 1/(2^2) + 1/(3^2) + ... + 1/(n^2)
This would be tedious to type out, and impossible for high values of n. Use vectorisation to compute x when n=100. What is the sum when n=10,000?
We’re interested in looking at the sum of the following sequence of fractions:
R
x = 1/(1^2) + 1/(2^2) + 1/(3^2) + ... + 1/(n^2)
This would be tedious to type out, and impossible for high values of n. Can you use vectorisation to compute x, when n=100? How about when n=10,000?
R
sum(1/(1:100)^2)
OUTPUT
[1] 1.634984R
sum(1/(1:1e04)^2)
OUTPUT
[1] 1.644834R
n <- 10000
sum(1/(1:n)^2)
OUTPUT
[1] 1.644834We can also obtain the same results using a function:
R
inverse_sum_of_squares <- function(n) {
sum(1/(1:n)^2)
}
inverse_sum_of_squares(100)
OUTPUT
[1] 1.634984R
inverse_sum_of_squares(10000)
OUTPUT
[1] 1.644834R
n <- 10000
inverse_sum_of_squares(n)
OUTPUT
[1] 1.644834Tip: Operations on vectors of unequal length
Operations can also be performed on vectors of unequal length, through a process known as recycling. This process automatically repeats the smaller vector until it matches the length of the larger vector. R will provide a warning if the larger vector is not a multiple of the smaller vector.
R
x <- c(1, 2, 3)
y <- c(1, 2, 3, 4, 5, 6, 7)
x + y
WARNING
Warning in x + y: longer object length is not a multiple of shorter object
lengthOUTPUT
[1] 2 4 6 5 7 9 8Vector x was recycled to match the length of vector
y
Key Points
- Use vectorized operations instead of loops.
Content from Functions Explained
Last updated on 2025-04-15 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- How can I write a new function in R?
Objectives
- Define a function that takes arguments.
- Return a value from a function.
- Check argument conditions with
stopifnot()in functions. - Test a function.
- Set default values for function arguments.
- Explain why we should divide programs into small, single-purpose functions.
If we only had one data set to analyze, it would probably be faster to load the file into a spreadsheet and use that to plot simple statistics. However, the gapminder data is updated periodically, and we may want to pull in that new information later and re-run our analysis again. We may also obtain similar data from a different source in the future.
In this lesson, we’ll learn how to write a function so that we can repeat several operations with a single command.
What is a function?
Functions gather a sequence of operations into a whole, preserving it for ongoing use. Functions provide:
- a name we can remember and invoke it by
- relief from the need to remember the individual operations
- a defined set of inputs and expected outputs
- rich connections to the larger programming environment
As the basic building block of most programming languages, user-defined functions constitute “programming” as much as any single abstraction can. If you have written a function, you are a computer programmer.
Defining a function
Let’s open a new R script file in the functions/
directory and call it functions-lesson.R.
The general structure of a function is:
R
my_function <- function(parameters) {
# perform action
# return value
}
Let’s define a function fahr_to_kelvin() that converts
temperatures from Fahrenheit to Kelvin:
R
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
We define fahr_to_kelvin() by assigning it to the output
of function. The list of argument names are contained
within parentheses. Next, the body of
the function–the statements that are executed when it runs–is contained
within curly braces ({}). The statements in the body are
indented by two spaces. This makes the code easier to read but does not
affect how the code operates.
It is useful to think of creating functions like writing a cookbook. First you define the “ingredients” that your function needs. In this case, we only need one ingredient to use our function: “temp”. After we list our ingredients, we then say what we will do with them, in this case, we are taking our ingredient and applying a set of mathematical operators to it.
When we call the function, the values we pass to it as arguments are assigned to those variables so that we can use them inside the function. Inside the function, we use a return statement to send a result back to whoever asked for it.
Tip
One feature unique to R is that the return statement is not required. R automatically returns whichever variable is on the last line of the body of the function. But for clarity, we will explicitly define the return statement.
Let’s try running our function. Calling our own function is no different from calling any other function:
R
# freezing point of water
fahr_to_kelvin(32)
OUTPUT
[1] 273.15R
# boiling point of water
fahr_to_kelvin(212)
OUTPUT
[1] 373.15Challenge 1
Write a function called kelvin_to_celsius() that takes a
temperature in Kelvin and returns that temperature in Celsius.
Hint: To convert from Kelvin to Celsius you subtract 273.15
Write a function called kelvin_to_celsius that takes a
temperature in Kelvin and returns that temperature in Celsius
R
kelvin_to_celsius <- function(temp) {
celsius <- temp - 273.15
return(celsius)
}
Combining functions
The real power of functions comes from mixing, matching and combining them into ever-larger chunks to get the effect we want.
Let’s define two functions that will convert temperature from Fahrenheit to Kelvin, and Kelvin to Celsius:
R
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
kelvin_to_celsius <- function(temp) {
celsius <- temp - 273.15
return(celsius)
}
Challenge 2
Define the function to convert directly from Fahrenheit to Celsius, by reusing the two functions above (or using your own functions if you prefer).
Define the function to convert directly from Fahrenheit to Celsius, by reusing these two functions above
R
fahr_to_celsius <- function(temp) {
temp_k <- fahr_to_kelvin(temp)
result <- kelvin_to_celsius(temp_k)
return(result)
}
Interlude: Defensive Programming
Now that we’ve begun to appreciate how writing functions provides an
efficient way to make R code re-usable and modular, we should note that
it is important to ensure that functions only work in their intended
use-cases. Checking function parameters is related to the concept of
defensive programming. Defensive programming encourages us to
frequently check conditions and throw an error if something is wrong.
These checks are referred to as assertion statements because we want to
assert some condition is TRUE before proceeding. They make
it easier to debug because they give us a better idea of where the
errors originate.
Checking conditions with stopifnot()
Let’s start by re-examining fahr_to_kelvin(), our
function for converting temperatures from Fahrenheit to Kelvin. It was
defined like so:
R
fahr_to_kelvin <- function(temp) {
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
For this function to work as intended, the argument temp
must be a numeric value; otherwise, the mathematical
procedure for converting between the two temperature scales will not
work. To create an error, we can use the function stop().
For example, since the argument temp must be a
numeric vector, we could check for this condition with an
if statement and throw an error if the condition was
violated. We could augment our function above like so:
R
fahr_to_kelvin <- function(temp) {
if (!is.numeric(temp)) {
stop("temp must be a numeric vector.")
}
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
If we had multiple conditions or arguments to check, it would take
many lines of code to check all of them. Luckily R provides the
convenience function stopifnot(). We can list as many
requirements that should evaluate to TRUE;
stopifnot() throws an error if it finds one that is
FALSE. Listing these conditions also serves a secondary
purpose as extra documentation for the function.
Let’s try out defensive programming with stopifnot() by
adding assertions to check the input to our function
fahr_to_kelvin().
We want to assert the following: temp is a numeric
vector. We may do that like so:
R
fahr_to_kelvin <- function(temp) {
stopifnot(is.numeric(temp))
kelvin <- ((temp - 32) * (5 / 9)) + 273.15
return(kelvin)
}
It still works when given proper input.
R
# freezing point of water
fahr_to_kelvin(temp = 32)
OUTPUT
[1] 273.15But fails instantly if given improper input.
R
# Metric is a factor instead of numeric
fahr_to_kelvin(temp = as.factor(32))
ERROR
Error in fahr_to_kelvin(temp = as.factor(32)): is.numeric(temp) is not TRUEChallenge 3
Use defensive programming to ensure that our
fahr_to_celsius() function throws an error immediately if
the argument temp is specified inappropriately.
Extend our previous definition of the function by adding in an
explicit call to stopifnot(). Since
fahr_to_celsius() is a composition of two other functions,
checking inside here makes adding checks to the two component functions
redundant.
R
fahr_to_celsius <- function(temp) {
stopifnot(is.numeric(temp))
temp_k <- fahr_to_kelvin(temp)
result <- kelvin_to_celsius(temp_k)
return(result)
}
More on combining functions
Now, we’re going to define a function that calculates the Gross Domestic Product of a nation from the data available in our dataset:
R
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat) {
gdp <- dat$pop * dat$gdpPercap
return(gdp)
}
We define calcGDP() by assigning it to the output of
function. The list of argument names are contained within
parentheses. Next, the body of the function -- the statements executed
when you call the function – is contained within curly braces
({}).
We’ve indented the statements in the body by two spaces. This makes the code easier to read but does not affect how it operates.
When we call the function, the values we pass to it are assigned to the arguments, which become variables inside the body of the function.
Inside the function, we use the return() function to
send back the result. This return() function is optional: R
will automatically return the results of whatever command is executed on
the last line of the function.
R
calcGDP(head(gapminder))
OUTPUT
[1] 6567086330 7585448670 8758855797 9648014150 9678553274 11697659231That’s not very informative. Let’s add some more arguments so we can extract that per year and country.
R
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
If you’ve been writing these functions down into a separate R script
(a good idea!), you can load in the functions into our R session by
using the source() function:
R
source("functions/functions-lesson.R")
Ok, so there’s a lot going on in this function now. In plain English, the function now subsets the provided data by year if the year argument isn’t empty, then subsets the result by country if the country argument isn’t empty. Then it calculates the GDP for whatever subset emerges from the previous two steps. The function then adds the GDP as a new column to the subsetted data and returns this as the final result. You can see that the output is much more informative than a vector of numbers.
Let’s take a look at what happens when we specify the year:
R
head(calcGDP(gapminder, year=2007))
OUTPUT
country year pop continent lifeExp gdpPercap gdp
12 Afghanistan 2007 31889923 Asia 43.828 974.5803 31079291949
24 Albania 2007 3600523 Europe 76.423 5937.0295 21376411360
36 Algeria 2007 33333216 Africa 72.301 6223.3675 207444851958
48 Angola 2007 12420476 Africa 42.731 4797.2313 59583895818
60 Argentina 2007 40301927 Americas 75.320 12779.3796 515033625357
72 Australia 2007 20434176 Oceania 81.235 34435.3674 703658358894Or for a specific country:
R
calcGDP(gapminder, country="Australia")
OUTPUT
country year pop continent lifeExp gdpPercap gdp
61 Australia 1952 8691212 Oceania 69.120 10039.60 87256254102
62 Australia 1957 9712569 Oceania 70.330 10949.65 106349227169
63 Australia 1962 10794968 Oceania 70.930 12217.23 131884573002
64 Australia 1967 11872264 Oceania 71.100 14526.12 172457986742
65 Australia 1972 13177000 Oceania 71.930 16788.63 221223770658
66 Australia 1977 14074100 Oceania 73.490 18334.20 258037329175
67 Australia 1982 15184200 Oceania 74.740 19477.01 295742804309
68 Australia 1987 16257249 Oceania 76.320 21888.89 355853119294
69 Australia 1992 17481977 Oceania 77.560 23424.77 409511234952
70 Australia 1997 18565243 Oceania 78.830 26997.94 501223252921
71 Australia 2002 19546792 Oceania 80.370 30687.75 599847158654
72 Australia 2007 20434176 Oceania 81.235 34435.37 703658358894Or both:
R
calcGDP(gapminder, year=2007, country="Australia")
OUTPUT
country year pop continent lifeExp gdpPercap gdp
72 Australia 2007 20434176 Oceania 81.235 34435.37 703658358894Let’s walk through the body of the function:
Here we’ve added two arguments, year, and
country. We’ve set default arguments for both as
NULL using the = operator in the function
definition. This means that those arguments will take on those values
unless the user specifies otherwise.
R
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
Here, we check whether each additional argument is set to
null, and whenever they’re not null overwrite
the dataset stored in dat with a subset given by the
non-null argument.
Building these conditionals into the function makes it more flexible for later. Now, we can use it to calculate the GDP for:
- The whole dataset;
- A single year;
- A single country;
- A single combination of year and country.
By using %in% instead, we can also give multiple years
or countries to those arguments.
Tip: Pass by value
Functions in R almost always make copies of the data to operate on
inside of a function body. When we modify dat inside the
function we are modifying the copy of the gapminder dataset stored in
dat, not the original variable we gave as the first
argument.
This is called “pass-by-value” and it makes writing code much safer: you can always be sure that whatever changes you make within the body of the function, stay inside the body of the function.
Tip: Function scope
Another important concept is scoping: any variables (or functions!)
you create or modify inside the body of a function only exist for the
lifetime of the function’s execution. When we call
calcGDP(), the variables dat, gdp
and new only exist inside the body of the function. Even if
we have variables of the same name in our interactive R session, they
are not modified in any way when executing a function.
Finally, we calculated the GDP on our new subset, and created a new data frame with that column added. This means when we call the function later we can see the context for the returned GDP values, which is much better than in our first attempt where we got a vector of numbers.
Challenge 4
Test out your GDP function by calculating the GDP for New Zealand in 1987. How does this differ from New Zealand’s GDP in 1952?
R
calcGDP(gapminder, year = c(1952, 1987), country = "New Zealand")
GDP for New Zealand in 1987: 65050008703
GDP for New Zealand in 1952: 21058193787
Challenge 5
The paste() function can be used to combine text
together, e.g:
R
best_practice <- c("Write", "programs", "for", "people", "not", "computers")
paste(best_practice, collapse=" ")
OUTPUT
[1] "Write programs for people not computers"Write a function called fence() that takes two vectors
as arguments, called text and wrapper, and
prints out the text wrapped with the wrapper:
R
fence(text=best_practice, wrapper="***")
Note: the paste() function has an argument
called sep, which specifies the separator between text. The
default is a space: ” “. The default for paste0() is no
space”“.
Write a function called fence() that takes two vectors
as arguments, called text and wrapper, and
prints out the text wrapped with the wrapper:
R
fence <- function(text, wrapper){
text <- c(wrapper, text, wrapper)
result <- paste(text, collapse = " ")
return(result)
}
best_practice <- c("Write", "programs", "for", "people", "not", "computers")
fence(text=best_practice, wrapper="***")
OUTPUT
[1] "*** Write programs for people not computers ***"Tip
R has some unique aspects that can be exploited when performing more complicated operations. We will not be writing anything that requires knowledge of these more advanced concepts. In the future when you are comfortable writing functions in R, you can learn more by reading the R Language Manual or this chapter from Advanced R Programming by Hadley Wickham.
Tip: Testing and documenting
It’s important to both test functions and document them: Documentation helps you, and others, understand what the purpose of your function is, and how to use it, and its important to make sure that your function actually does what you think.
When you first start out, your workflow will probably look a lot like this:
- Write a function
- Comment parts of the function to document its behaviour
- Load in the source file
- Experiment with it in the console to make sure it behaves as you expect
- Make any necessary bug fixes
- Rinse and repeat.
Formal documentation for functions, written in separate
.Rd files, gets turned into the documentation you see in
help files. The roxygen2
package allows R coders to write documentation alongside the function
code and then process it into the appropriate .Rd files.
You will want to switch to this more formal method of writing
documentation when you start writing more complicated R projects. In
fact, packages are, in essence, bundles of functions with this formal
documentation. Loading your own functions through
source("functions.R") is equivalent to loading someone
else’s functions (or your own one day!) through
library("package").
Formal automated tests can be written using the testthat package.
Key Points
- Use
functionto define a new function in R. - Use parameters to pass values into functions.
- Use
stopifnot()to flexibly check function arguments in R. - Load functions into programs using
source().